Events: Master Classes
Master Classes
Event Date: [ 7.31.15 ]
Location:
Spring Mountain Vineyard
St. Helena, CA
United States(ED. NOTE: In 2015, Edge presented "A Short Course in Superforecasting" with political and social scientist Philip Tetlock. Superforecasting is back in the news this week thanks to the UK news coverage of comments by Boris Johnson's chief adviser Dominic Cummings, who urged journalists to "read Philip Tetlock's Superforecasters [sic], instead of political pundits who don't know what they're talking about.")


PHILIP E. TETLOCK, political and social scientist, is the Annenberg University Professor at the University of Pennsylvania, with appointments in Wharton, psychology and political science. He is co-leader of the Good Judgment Project, a multi-year forecasting study, author of Expert Political Judgment, co-author of Counterfactual Thought Experiments in World Politics (with Aaron Belkin), and co-author of Superforecasting: The Art & Science of Prediction (with Dan Gardner). Further reading on Edge: "How to Win at Forecasting: A Conversation with Philip Tetlock" (December 6, 2012). Philip Tetlock's Edge Bio Page.
CLASS I — Forecasting Tournaments: What We Discover When We Start Scoring Accuracy
It is as though high status pundits have learned a valuable survival skill, and that survival skill is they've mastered the art of appearing to go out on a limb without actually going out on a limb. They say dramatic things but there are vague verbiage quantifiers connected to the dramatic things. It sounds as though they're saying something very compelling and riveting. There's a scenario that's been conjured up in your mind of something either very good or very bad. It's vivid, easily imaginable.
It turns out, on close inspection they're not really saying that's going to happen. They're not specifying the conditions, or a time frame, or likelihood, so there's no way of assessing accuracy. You could say these pundits are just doing what a rational pundit would do because they know that they live in a somewhat stochastic world. They know that it's a world that frequently is going to throw off surprises at them, so to maintain their credibility with their community of co-believers they need to be vague. It's an essential survival skill. There is some considerable truth to that, and forecasting tournaments are a very different way of proceeding. Forecasting tournaments require people to attach explicit probabilities to well-defined outcomes in well-defined time frames so you can keep score.
CLASS II — Tournaments: Prying Open Closed Minds in Unnecessarily Polarized Debates
Tournaments have a scientific value. They help us test a lot of psychological hypotheses about the drivers of accuracy, they help us test statistical ideas; there are a lot of ideas we can test in tournaments. Tournaments have a value inside organizations and businesses. A more accurate probability helps to price options better on Wall Street, so they have value.
I wanted to focus more on what I see as the wider societal value of tournaments and the potential value of tournaments in depolarizing unnecessarily polarizing policy debates. In short, making us more civilized. ...
There is well-developed research literature on how to measure accuracy. There is not such well-developed research literature on how to measure the quality of questions. The quality of questions is going to be absolutely crucial if we want tournaments to be able to play a role in tipping the scales of plausibility in important debates, and if you want tournaments to play a role in incentivizing people to behave more reasonably in debates.

CLASS III — Counterfactual History: The Elusive Control Groups in Policy Debates
There's a picture of two people on slide seventy-two, one of whom is one of the most famous historians in the 20th century, E.H. Carr, and the other of whom is a famous economic historian at the University of Chicago, Robert Fogel. They could not have more different attitudes toward the importance of counterfactuals in history. For E.H. Carr, counterfactuals were a pestilence, they were a frivolous parlor game, a methodological rattle, a sore loser's history. It was a waste of cognitive effort to think about counterfactuals. You should think about history the way it did unfold and figure out why it had to unfold the way it did—almost a prescription for hindsight bias.
Robert Fogel, on the other hand, approached it more like a scientist. He quite correctly recognized that if you want to draw causal inferences from any historical sequence, you have to make assumptions about what would have happened if the hypothesized cause had taken on a different value. That's a counterfactual. You had this interesting tension. Many historians do still agree, in some form, with E.H. Carr. Virtually all economic historians would agree with Robert Fogel, who's one of the pivital people in economic history; he won a Nobel Prize. But there's this very interesting tension between people who are more open or less open to thinking about counterfactuals. Why that is, is something that is worth exploring.

CLASS IV — Skillful Backward and Forward Reasoning in Time: Superforecasting Requires "Counterfactualizing"
A famous economist, Albert Hirschman, had a wonderful phrase, "self-subversion." Some people, he thought, were capable of thinking in self-subverting ways. What would a self-subverting liberal or conservative say about the Cold War? A self-subverting liberal might say, "I don’t like Reagan. I don’t think he was right, but yes, there may be some truth to the counterfactual that if he hadn’t been in power and doing what he did, the Soviet Union might still be around." A self-subverting conservative might say, "I like Reagan a lot, but it’s quite possible that the Soviet Union would have disintegrated anyway because there were lots of other forces in play."
Self-subversion is an integral part of what makes superforecasting cognition work. It’s the willingness to tolerate dissonance. It’s hard to be an extremist when you engage in self-subverting counterfactual cognition. That’s the first example. The second example deals with how regular people think about fate and how superforecasters think about it, which is, they don’t. Regular people often invoke fate, "it was meant to be," as an explanation for things.

CLASS V — Condensing it All Into Four Big Problems and a Killer App Solution
The beauty of forecasting tournaments is that they’re pure accuracy games that impose an unusual monastic discipline on how people go about making probability estimates of the possible consequences of policy options. It’s a way of reducing escape clauses for the debaters, as well as reducing motivated reasoning room for the audience.
Tournaments, if they’re given a real shot, have a potential to raise the quality of debates by incentivizing competition to be more accurate and reducing functionalist blurring that makes it so difficult to figure out who is closer to the truth.


In the circle of clairvoyants: At a vineyard north of San Francisco, Philip Tetlock of the University of Pennsylvania (left) presented his findings. Initially skeptical was Nobel Laureate Kahneman (third from left). Photo: John Brockman / edge.org
ATTENDEES:
Robert Axelrod, Political Scientist; Walgreen Professor for the Study of Human Understanding, U. Michigan; Author, The Evolution of Cooperation; Member, National Academy of Sciences; Recipient, the National Medal of Science; Stewart Brand, Founder, The Whole Earth Catalog; Co-Founder, The Well; Co-Founder, The Long Now Foundation; Author, Whole Earth Discipline; John Brockman, Editor, Edge; Author, The Third Culture; Rodney Brooks, Panasonic Professor of Robotics (emeritus), MIT; Founder, Chmn/CTO, Rethink Robotics; Author, Flesh and Machines; Brian Christian, Philosopher, Computer Scientist, Poet; Author, The Most Human Human; Wael Ghonim, Pro-democracy leader of the Tarir Square demonstrations in Egypt; Anonymous administrator of the Facebook page, "We are all Khaled Saeed"; W. Daniel Hillis, Physicist; Computer Scientist; Chairman, Applied Minds; Author, The Pattern on the Stone; Jennifer Jacquet, Assistant Professor of Environmental Studies, NYU; Author, Is Shame Necessary?; Daniel Kahneman, Professor Emeritus of Psychology, Princeton; Author, Thinking, Fast and Slow; Winner of the 2013 Presidential Medal of Freedom; Recipient of the 2002 Nobel Prize in Economic Sciences; Salar Kamangar, Senior Vice President, Google; Fmr head of YouTube; Dean Kamen, Inventor and Entrepreneur, DEKA Research; Andrian Kreye, Feuilleton Editor, Sueddeutsche Zeitung, Munich; Peter Lee, Corp. VP, Microsoft Research; Former Founder / Director, DARPA's technology office; Former Head, Carnegie Mellon Computer Science Department & CMU's Vice Provost for Research; Margaret Levi, Political Scientist, Director, Center For Advanced Study in Behavioral Sciences (CASBS), Stanford University; Barbara Mellers, Psychologist; George Heyman University Professor at UPennsylvania; Past President, Society of Judgment and Decision Making; Ludwig Siegele, Technology Editor, The Economist; Rory Sutherland, Executive Creative Director and Vice-Chairman, OgilvyOne London; Vice-Chairman, Ogilvy & Mather UK; Columnist, The Spectator; Philip Tetlock, Political and Social Scientist; Annenberg University Professor at UPenn; Author, Expert Political Judgment; and (with Dan Gardner) Superforecasting (forthcoming); Anne Treisman, James S. McDonnell Distinguished University Professor Emeritus of Psychology at Princeton; Recipient, National Medal of Science; D.A.Wallach, Recording Artist; Songwriter; Artist in Residence, Spotify; Hi-Tech Investor
Master Classes
Event Date: [ 7.15.11 ]
Location:
Spring Mountain Vineyard, St. Helena,
St. Helena,, CA
United States
























Anne Treisman and Daniel Kahneman
Anne Treisman and Daniel Kahneman
Ben Carey, Steven Pinker, and Michael Gazzaniga
Ben Carey, Steven Pinker, and Michael Gazzaniga
Daniel Kahneman class
Daniel Kahneman class
Daniel Kahneman, Jennifer Jacquet, and Eva Wisten
Daniel Kahneman, Jennifer Jacquet, and Eva Wisten
Eva Wisten and Jennifer Jacquet
Eva Wisten and Jennifer Jacquet
Eva Wisten and Jim Giles
Eva Wisten and Jim Giles
Greg Miller and Lucy Odling-Smee
Greg Miller and Lucy Odling-Smee
Anne Treisman, Steven Pinker, Leda Cosmides, John Tooby, and Elaine Pagels
Anne Treisman, Steven Pinker, Leda Cosmides, John Tooby, and Elaine Pagels
Jaron Lanier, Jennifer Jacquet, and Nick Pritzker
Jaron Lanier, Jennifer Jacquet, and Nick Pritzker
Jennie Ripps, Ben Carey, and Max Brockman
Jennie Ripps, Ben Carey, and Max Brockman
Jennifer Jacquet
Jennifer Jacquet
John Tooby
John Tooby
Katinka Matson, Ben Carey, and Elaine Pagels
Katinka Matson, Ben Carey, and Elaine Pagels
Leda Cosmides and Jaron Lanier
Leda Cosmides and Jaron Lanier
Martin Nowak class
Martin Nowak class
Martin Nowak and Elaine Pagels
Martin Nowak and Elaine Pagels
Max Brockman and Katinka Matson
Max Brockman and Katinka Matson
Max Brockman
Max Brockman
Michael Gazzaniga class
Michael Gazzaniga class
Nick Pritzker and Stewart Brand
Nick Pritzker and Stewart Brand
Sean Parker, Jennie Ripps, and Max Brockman
Sean Parker, Jennie Ripps, and Max Brockman
Spring Mountain Vineyard
Spring Mountain Vineyard
Steven Pinker class
Steven Pinker class
Steven Pinker and Daniel Kahneman
Steven Pinker and Daniel Kahneman
Daniel Kahneman, Martin Nowak, Steven Pinker, Leda Cosmides, Michael Gazzaniga, Elaine Pagels
"We'd certainly be better off if everyone sampled the fabulous Edge symposium, which, like the best in science, is modest and daring all at once." — David Brooks, New York Times column
In July, Edge held its annual Master Class in Napa, California, on the theme: "The Science of Human Nature": Princeton psychologist Daniel Kahneman on the marvels and the flaws of intuitive thinking; Harvard mathematical biologist Martin Nowak on the evolution of cooperation; Harvard psychologist Steven Pinker on the history of violence; UC-Santa Barbara evolutionary psychologist Leda Cosmides on the architecture of motivation; UC-Santa Barbara neuroscientist Michael Gazzaniga on neuroscience and the law; and Princeton religious historian Elaine Pagels on The Book of Revelation. In the coming weeks we will publish the complete video, audio, and texts. For publication schedule and details, see below.
Spring Mountain Vineyard, St. Helena, Napa, CA
Friday July 15 to Sunday, July 17th

DANIEL KAHNEMAN: "THE MARVELS AND THE FLAWS OF INTUITIVE THINKING"
The power of settings, priming, and unconscious thinking, all are a major change in psychology. I can't think of a bigger change in my lifetime. You were asking what's exciting? That's exciting, to me.

Eugene Higgins Professor of Psychology, Princeton University; Recipient, the 2002 Nobel Prize in Economic Sciences; Author, Thinking Fast and Slow (forthcoming, October 25th). Daniel Kahneman's Edge Bio Page
[Continue to Daniel Kahneman's Edge Master Class]

MARTIN NOWAK: "THE EVOLUTION OF COOPERATION"
Why has cooperation, not competition, always been the key to the evolution of complexity?

Mathematical Biologist, Game Theorist; Professor of Biology and Mathematics, Director, Center for Evolutionary Dynamics, Harvard University; Author, SuperCooperators: Altruism, Evolution, and Why We Need Each Other to Succeed. Martin Nowak's Edge Bio Page
[Continue to Martin Nowak's Edge Master Class]

STEVEN PINKER: "A HISTORY OF VIOLENCE"
What may be the most important thing that has ever happened in human history is that violence has gone down, by dramatic degrees, and in many dimensions all over the world and in many spheres of behavior: genocide, war, human sacrifice, torture, slavery, and the treatment of racial minorities, women, children, and animals.

Harvard College Professor and Johnstone Family Professor of Psychology; Harvard University. Author, The Language Instinct, How the Mind Works, and The Better Angels Of Our Nature: How Violence Has Declined (forthcoming, October 4th). Steven Pinker's Edge Bio Page
[Continue to Steven Pinker's Edge Master Class]

LEDA COSMIDES: "THE ARCHITECTURE OF MOTIVATION"
Recent research concerning the welfare of others, etc. affects not only how to think about certain emotions, but also overturns how most models of reciprocity and exchange, with implications about how people think about modern markets, political systems, and societies. What are these new approaches to human motivation?

Professor of Psychology and Co-director (with John Tooby) of Center for Evolutionary Psychology at the University of California, Santa Barbara. Leda Cosmides's Edge Bio Page
[Continue to Leda Cosmides's Edge Master Class]

MICHAEL GAZZANIGA: "NEUROSCIENCE AND JUSTICE"
Asking the fundamental question of modern life. In an enlightened world of scientific understandings of first causes, we must ask: are we free, morally responsible agents or are we just along for the ride?

Neuroscientist; Professor of Psychology & Director, SAGE Center for the Study of Mind, University of California, Santa Barbara; Human: Who's In Charge? (forthcoming, November 15th). Michael Gazzaniga's Edge Bio Page
[Continue to Michael Gazzaniga's Edge Master Class]

ELAINE PAGELS: "THE BOOK OF REVELATION: PROPHECY AND POLITICS"
Why is religion still alive? Why are people still engaged in old folk takes and mythological stories — even those without rational and ethical foundations.

Harrington Spear Paine Professor of Religion, Princeton University; Author The Gnostic Gospels; Beyond Belief; and Revelations: Visions, Prophecy, and Politics in the Book of Revelation (forthcoming, March 6, 2012). Elaine Pagels's Edge Bio Page
[Continue to Elaine Pagels's Edge Master Class]
"Open-minded, free ranging, intellectually playful ... an unadorned pleasure in curiosity, a collective expression of wonder at the living and inanimate world ... an ongoing and thrilling colloquium." — Ian McEwan in The Telegraph

Villa Miravalle at Spring Mountain
The Edge Master Class 2011 was held at Villa Miravelle at Spring Mountain Vineyard in St. Helena, California.
Built 1884 in Saint Helena, CA, by Mexican-American Tiburcio Parrott, the majestic residence dominates the surrounding vineyards and includes spires, wraparound verandas, a conservatory, a grand stone tower, massive front double doors with exquisite stained glass, and a six-story high cupola. Miravalle was designed by architect Albert Schroepfer, who had designed acclaimed structures at Inglenook and Beringer Wineries, and San Fransisco's Orpheum Theatre. ... Tiburcio died within ten years, and Miravalle remained empty for the next seventy. In 1974 Spring Mountain Vineyard and winery were established on the surrounding property.
The Vineyard was bought by Edge member Jacqui (Jacob) Eli Safra in 1992, after which he consolidated several properties into the current 900-acre property, the largest contiguous vineyard in Napa. Safra, a Swiss investor, is a descendant of the Lebanon-Swiss Jewish Safra banking family. In addition to Spring Mountain Vineyards, his other investments include Encyclopædia Britannica and Merriam-Webster. The entire Edge community wishes to thank him for his thoughtfuness and generosity. And we wish to express our appreciation to General Manager George Peterson, and Customer Relationship Director Leah Smith for their help in organizing a memorable weekend.
Master Classes
Event Date: [ 12.27.10 ]
Location:
United States







We make a mistake when we think of cancer as a noun. It is not something you have, it is something you do. Your body is probably cancering all the time. What keeps it under control is a conversation that is happening between your cells, and the language of that conversation is proteins. Proteomics will allow us to listen in on that conversation, and that will lead to much better way to treat cancer.

Introduction
by John Brockman
The leaders of the National Cancer Institute," says Danny Hillis, "are very keenly aware of how little progress has actually been made in the treatment of cancer. This is something they pay a lot of attention to. They're thinking very laterally in giving funding to people like me to work on cancer."
"What they've said is 'Let's bring some new kinds of thinking to this, and create a program where we have physical scientists be the principle investigators, partnered with the co-investigators who are clinicians and biological scientists.' I'm partnering with David Agus, for example. But giving money to the physical scientist is a pretty radical idea, you can imagine it is very controversial within the biological community."
"NCI has started a few of these centers, and given them five years to work. They need to be interdisciplinary and geographically distributed. Our center at USC has people all over the United States involved in it, like Cold Spring Harbor, Stanford, Arizona, UT, NYU and CalTech.
"As a result, Hillis is the newly appointed professor of research medicine at the Keck School of Medicine at the University of Southern California (USC). And he is the principal investigator of a five-year government program on cancer.
The University of Southern California Physical Sciences-Oncology Center's (USC PS-OC) overall goal is to thoroughly understand therapeutic response.
Investigators will establish a predictive model of cancer that they can utilize to determine tumor steady state growth and drug response, particularly those involved in the hematological malignancies of acute myeloid leukemia and non-Hodgkin lymphoma. Furthermore, multi-scale physical measurements will be unified with sophisticated modeling approaches to facilitate the development of a model that can derive the tumor's traits during its growth and after any distress, such as chemotherapeutic treatment. These investigators will apply pioneering measurement platforms to resolve real-time protein interactions and protein abundance and to characterize protein modifications. Appropriately, these studies will also address tumor and host response to therapy using a systems approach. Overall, the predictive tumor response model should enable clinicians to determine the most efficacious therapies a priori and reduce deleterious side effects.
Hillis continues..."We misunderstand cancer by making it a noun. Instead of saying, "My house has water", we say, "My plumbing is leaking." Instead of saying, "I have cancer", we should say, "I am cancering." The truth of the matter is we're probably cancering all the time, and our body is checking it in various ways, so we're not cancering out of control. Probably every house has a few leaky faucets, but it doesn't matter much because there are processes that are mitigating that by draining the leaks. Cancer is probably something like that.
"In order to understand what's actually going on, we have to look at the level of the things that are actually happening, and that level is proteomics. Now that we can actually measure that conversation between the parts, we're going to start building up a model that's a cause-and-effect model: This signal causes this to happen, that causes that to happen. Maybe we will not understand to the level of the molecular mechanism but we can have a kind of cause-and-effect picture of the process. More like we do in sociology or economics.
"Last year's EdgeMaster Class in Los Angeles featured George Church and Craig Venter lecturing on Synthetic Genomics. Hillis points out that the genome is used to construct things, and that it's not the best place for analysis of what's going on. "Certainly," he says, "there are times it is useful, but I don't think that's where most of the information is.
If you think in terms of computer models, think of proteomics as a debugging tool for genomics programs. "When you write a computer program, the first thing you do is you try to run it, and it almost always has a bug in it, so you see what happens, and you debug it, you stop it in the middle of running, and you see what the state of the system is, and you understand what your bug is, and then you change the program. The proteome is the state".
"Proteomics was made possible by genomics. It builds on top of genomics. I guess it's true in some theoretical sense that eventually you might not even bother to look at the genome if you can see the whole proteome, but in practice, it's been very important."
"The genome is the instructions for the cell. That's very important if you want to do manipulation. If you want to actually affect the pathway, then that is the level at which you need to manipulate things. You want to knock out a gene, or modify a gene. Experimentally, being able to read and write the genome is incredibly important. But if you want to use it as a diagnostic for what's going wrong with a particular individual, it will be unusual for that information to be in the genome."
I am talking to Hillis in Villa Miravelle, an historic, exotic mansion with an interesting history, built in 1884 in Saint Helena, CA, by Mexican-American Tiburcio Parrott. In 1974 Spring Mountain Vineyard and winery were established on the surrounding property.

Swiss financier Jacob E. "Jacqui" Safra acquired the Spring Mountain Vineyard in 1991 and through acquisitions expanded the property to 225 acres of vineyard on an 850 acre estate, now the largest vineyard in terms of contiguous acreage in the Napa Valley. Safra, a member of the Edge community, graciously offered the use of Spring Mountain Vineyard as the venue for the Edge Master Class 2010.
This year, to try something different, Edge ran a conference on the East Coast in July (See "The New Science of Morality") There was no intent to run the usual Master Class in California, until Safra came forth with his generous offer, followed by a conversation I had with Danny Hillis a week ago on "proteomics". Given his excitement about the prospects of his new research program coupled by his track record as the man who broke the von Neumann bottleneck to give us the massively parallel computer, I didn't hesitate to announce this event.
The event occurred with one week's notice, the same week as the "Sci-FOO Camp" at Google and the first "Techonomy" conference at Lake Tahoe, both interesting, even exciting events. In the end, among all the usual suspects, it was Hillis, Stewart Brand, and myself who showed up for a weekend at the most exquisite vineyard property in California (See photos below). The weather was beautiful. We were surrounded by dozens of bottles of Safra's prize-winning Spring Mountain Elivette (2005).

Stewart Brand, John Brockman, Daniel Hillis
We a 2-part Edge Master Class which is available below in three formats: streaming viideo (two one-hour talks), audio download, and text (including a printable text file of Parts I & II) .
- JB
W. DANIEL ("DANNY") HILLIS is Chairman and Chief Technology Officer of Applied Minds, a research and development company creating a range of new products and services in software, entertainment, electronics, biotechnology and mechanical design. Hillis is also Judge Widney Professor of Engineering and Medicine of the University of Southern California (USC), professor of research medicine at the Keck School of Medicine, and research professor of engineering at the Viterbi School of Engineering. Previously, Hillis was Vice President, Research and Development at Walt Disney Imagineering, and Disney Fellow. He developed new technologies and business strategies for Disney's theme parks, television, motion pictures, Internet and consumer products businesses.
An inventor, scientist, engineer, author, and visionary, Hillis pioneered the concept of parallel computers that is now the basis for most supercomputers, as well as the RAID disk array technology used to store large databases. He holds over 150 U.S. patents, covering parallel computers, disk arrays, forgery prevention methods, and various electronic and mechanical devices.
As a student at MIT, Hillis began to study the physical limitations of computation and the possibility of building highly parallel computers. This work culminated in 1985 with the design of a massively parallel computer with 64,000 processors. He named it the Connection Machine. During this period at MIT Hillis co-founded Thinking Machines Corp. to produce and market the Connection Machine.
Thinking Machines Corp. was the leading innovator in massive parallel supercomputers and RAID disk arrays. In addition to designing the company's major products, Hillis worked closely with his customers in applying parallel computers to problems in astrophysics, aircraft design, financial analysis, genetics, computer graphics, medical imaging, image understanding, neurobiology, materials science, cryptography and subatomic physics. At Thinking Machines, he built a technical team comprised of scientists and engineers that were widely acknowledged to have been among the best in the industry.
In 2005, Hillis and others from Applied Minds initiated Metaweb Technologies to develop a semantic data storage infrastructure for the Internet, and Freebase, an "open, shared database of the world's knowledge". That company was recently acquired by Google.
Hillis has published scientific papers in journals such as Science, Nature, Modern Biology, Communications of the ACM andInternational Journal of Theoretical Physics and is an editor of several other scientific journals, including Artificial Life, Complexity, Complex Systems, Future Generation Computer Systems andApplied Mathematics. He has also written extensively on technology and its implications for publications such as Newsweek, Wired, Forbes ASAP and Scientific American. He is the author of The Pattern on the Stone. He is a Member of the National Academy of Engineering, a Fellow of the Association of Computing Machinery, a Fellow of the International Leadership Forum, and a Fellow of the American Academy of Arts and Sciences. He is Co-Chair of Long Now Foundation and the designer of a 10,000-year mechanical clock.
We are pleased to present below the entire 2-part Edge Master Class which is available below in three formats: streaming viideo, audio download, and text.
![]()
CANCERING
Listening In On The Body's Proteomic Conversation (Part I)
Right now, I am asking a lot of questions about cancer, but I probably should explain how I got to that point, why somebody who's mostly interested in complexity, and computers, and designing machines, and engineering, should be interested in cancer. I'll tell you a little bit about cancer, but before I tell you about that, I'm going to tell you about proteomics, and before I tell you about proteomics, I want to get you to think about genomics differently because people have heard a lot about genes, and genomics in the last few years, and it's probably given them a misleading idea about what's important, how diseases work, and so on. ...
~~~
Printable text file (Parts I & II)
You've probably heard the genome described as like a blueprint for producing an organism. That's a very misleading analogy because a blueprint is interesting because it says how everything is connected, and how the parts relate to each other. In fact, the genome, at least the part of the genome that we understand how to read, actually doesn't tell you that at all. It's kind of a list of the parts. It does have some control information on it about when different parts should be made, but for the most part we don't know how to read that control information right now. What we know how to read is the parts list. While that's a very useful thing, it's probably not the most important thing that we need to know to understand what's going on.CANCERING: Listening In On The Body's Proteomic Conversation (PART I)
W. Daniel Hillis
Right now, I am asking a lot of questions about cancer, but I probably should explain how I got to that point, why somebody who's mostly interested in complexity, and computers, and designing machines, and engineering, should be interested in cancer. I'll tell you a little bit about what I am doing in cancer, but before I tell you about that, I'm going to tell you about proteomics. Before I tell you about proteomics, I want to get you to think about genomics differently because people have heard a lot about genes and genomics in the last few years, and it's probably given them a misleading idea about what's important, how diseases work, and so on.
Let me start by talking about genes, and giving you a different way of looking at genes, I want to start by clearing up, well maybe not misunderstandings, but putting a different emphasis on how genes work. That will explain why I'm interested in proteomics, and that will explain why I'm interested in cancer.
An analogy might be restaurants. Let's say you were trying to understand the difference between a great restaurant and a bad restaurant, and what you had to work with was a list of the ingredients that they had in their storehouse. Sure enough, if you snuck in at night and looked at their inventory list, you might be able to tell some things about the restaurant. You could probably tell the difference between a French restaurant, and a Chinese restaurant just by the ingredients list. And indeed, you can tell the difference between a European person, and an Oriental person just by looking at their ingredients list, but you probably can't tell a lot about what their personality is like.
Now, sometimes you can tell about defects, so if a restaurant was completely missing salt, or they only had lard for oil, you could say, "Well, this restaurant might be improved if they started using salt, or if they had some butter instead of lard", or something like that. So there might be some gross things that you can tell about inadequacies, that they were missing a key ingredient, something was broken about the ingredients list, but to really understand whether the food was good or not, or how they were making food, you really have to watch what's going on in the kitchen, and watch the process. You have to actually watch the dynamic process; the list of ingredients doesn't work.
The way I think about this is more like computer programs. The genome is like a listing of your operating system, but missing all the control information, so missing all the jumps, and things like that, and that's a fairly useless thing to have if you're trying to figure out, if you're trying to debug a program. It's not totally useless, but it's not that informative. What a programmer would really want to know is they'd like to dynamically look at what's going on inside the machine, what's getting loaded into the registers. That kind of dynamic trace is the much more useful thing for debugging them in kind of a partial listing of the code. If I put it that way, you might ask what's the big deal about the genome, why all the excitement about genomics?
I think it has a couple of historical reasons. One of them is the gene is the great theoretical triumph of biology, it's the one kind of theoretical construct that was predicted. Like the physicists predicted there ought to be a positron, and when they looked, there was a positron. That happens all the time in physics. The equation says there should be a black hole, and we look, and we find black holes. In biology, that almost never happens, and the great dramatic example of it happening was genes. So genes were kind of theoretically predicted by Mendel and they were the core of what Darwin needed, that unit of inheritance. Then Watson and Crick looked and actually discovered it! It was like actually finding the black hole that was predicted. That was in some sense the most exciting thing that ever happened in biology, and since it so stands out, there's nothing close to that, it almost has a religious significance in biology. It is the triumph of the one great theory.
The other thing about it, a practical thing, is that it turned out that people like Kary Mullis worked out this very neat way with tools that the biologists had on their bench, so they could actually measure a gene. In fact, you can almost do genetics in your own kitchen with a few extra pieces of equipment, if you have the right enzymes around. You heat something up, and cool it down, and heat it up, and cool it down, and then you pour it in some jello, run an electric field across it and you actually get a read-out of this nice, digital picture.
So not only was it a theoretical construct that had been predicted by biology, but it was also accessible to experiments with the stuff that people had lying around in their labs. Of course, now we sequence genes with much more sophisticated equipment that does it much more rapidly. But it got its start because everybody could do it in their lab. They could see the genes, so everybody could get in the genetics business immediately, and start getting really interesting genetics results.
For instance, the field of zoology was transformed by being able to tell what's related to what, like kind of the trick of telling the difference between the French restaurant and the Chinese restaurant. By looking at the ingredients you could find the complete tree of family relationships, and so there's a huge amount of good science that suddenly became possible. You could get a lot of hard data. Of course, people immediately looked at what medical applications it could have.
There are dramatic medical examples where you're missing a key ingredient, or one of your ingredients is broken, when there is a disease associated with that - a mutation in a gene, or a missing gene, or duplicated gene or something like that. Cystic fibrosis is an example of that, where the problem is in a single gene. So there are definitely examples like that, conditions that can be identified, and understood in a certain sense by looking at this parts list, or looking at this ingredients list. But if you really want to know what's going on, in most cases a much more interesting thing to do is to look at the dynamics. That is in the proteins that are actually getting generated. Some of them are getting generated directly from genes, some of them are getting generated and then modified by after they are produced. There's a lot that happens after the genetics. And the proteins are controlling which genes are expressed.
So, to me, there is a much more interesting kind of analogy, based on process. The analogy we have so far is about structure. We emphasize the structure of things, so we think of the building blocks, and the things that get built, and the parts. I think it's much more interesting to look at the process that builds all of these parts.
It's true that the human body is an amazing structure, but what's much more interesting is the process that builds it, that maintains it, modifies it. That's not really in the genes, it's in the conversation that's happening between all the parts of the body, and the conversation is happening within the little molecular machines within the cell, or between the cells in the body. Your body has tens of trillions of cells in it, more than the population of the earth, and all these cells are talking to each other, sending each other signals, there's signaling going on within the cell.
To emphasize this other way of looking at it I like to look at the genome, not just as a parts list, but as the vocabulary list for this conversation. It's a useful thing to know, but the really interesting thing to do is to listen in on the conversation. What are these machines all saying to each other? That's what proteomics is about.
Proteomics is the study of all the proteins. "Omics" means "the study of all". The idea became popular when people like Wally Gilbert who started saying, "We should have all the human genes." Then by generalization, people were saying, "Well, we should know all the proteins in the body, we should know all the connections between neurons, and we should know all the metabolites." There are a lot of different kinds of "omics".
What is really interesting about proteomics, is the dynamic conversation; it's the study of the molecules that the genes are making, the ones that are controlling the genome. It is the conversation between the parts. This conversation is happening within the cell, and between cells, the elements of this conversation are proteins that are being sent around, and being absorbed by the cells, or being sent from one part of the cell to another. It's taking place in the medium of proteins, and so if you could see where all of those proteins are, and how they're dynamically changing, then you would, in fact, be listening in on the conversation. That would be a great thing to hear.
Biologists have recognized for a long time that it's a great thing to do. They've tried to do it. It's turned out to be technically much, much more difficult than genomics, for a couple of reasons. One of them is it's essentially an analog process, not a digital process. It matters how much of the protein is there. But another thing is there just wasn't this wonderful technology for dealing with it like replicating DNA.
You couldn't really do it well with the equipment that was lying around in the lab. People have tried to do it, but it was a very unrepeatable process, a very noisy process, and so the first publications about it tended to be wrong because people had mismeasured it, they couldn't measure the same thing a second time. So basically what happened was that it kind of got a bad name in biology, and people said, "Well, we can't get much useful information out of this", because, in fact, they couldn't get it with the stuff they had lying around the lab.
That's where I came in. I had looked at this in the abstract, years and years ago, I thought that this would be a great thing to do, but when I looked in to the details, I thought it would be too difficult. Then just a few years ago, I got approached by the oncologist, David Agus, who said, "We really need this information for treating cancer patients", and he convinced me to look at it again with the new tools that had come along.
The tools typically are things like mass spectrometers for weighing molecules, and liquid chromatography, which is basically sliding a molecule past a bunch of other molecules, and seeing how much it sticks. We can also make antibodies that stick to very specific molecules. That is a set of tools that hasn't changed very much, but when I started looking at it, I realized that the big problem was that people were using these tools basically in a lab bench, and treating it almost like they were treating genomics, as if it was a digital process. They were going through a sequence of experimental steps, but the way that they were controlling it wasn't possibly good enough to even get the same result twice if they measured the same sample, much less to look for subtle things in the changes.
I realized that it really needed a couple of other things, one of which is some better application of physics, which is how the instruments were actually tuned to do this problem. Another thing it needed was some plain process engineering. What was required was much more like making a semiconductor line than it was like sequencing DNA. There were many, many steps that had to be refined, and highly, highly controlled in order to get a repeatable result in protein. So this was essentially an engineering problem.
There are certainly hundreds of thousands of different protein variants, and maybe more. Nobody really knows which variations are significant. But certainly every gene produces a protein, and then those proteins get modified by the processes, and combined, and produce other proteins, and so on. The big problem was that there was no way of looking at all the proteins, say in a drop of blood that was repeatable, that you could measure the same drop of blood and see the same proteins, and part of the problem is because they occur in vastly different amounts. Some of them are a million times more diluted than others, so there's a huge dynamic range.
But also there are hundreds of steps in the process of measuring them. So if you're doing this with graduate students in a bio lab, and one of them goes and has a cup of coffee at one step, and you leave it 15 seconds longer than an enzyme, you get a completely different result. What needs to be done is a super tightly controlled engineering process.
Since that was essentially an engineering problem, I thought that could be an interesting problem for an engineer like me to work on, so I started working on that. Then it turns out that once you get that, there's a huge mathematical problem at the end, which I was also interested in. It was a computing problem, of interpreting all of these results. If you know that this protein is going up or down, how do you make any sense of that, and correlate that to anything useful. That is essentially a computing problem. Since it was a computing problem, and an engineering problem, I thought that I had something to bring to the table, and started working in the area really just to get the engineering worked out.
Applied Minds can do projects in the exploratory stage without going off and getting any funding; we do it with our own profits from other projects, so we started exploring proteomics with David Agus. And that's how we realized that we could do it if we could really build a line like an assembly line for doing it, which involved robotics, and changing the mass spectrometers, and things like that.
We got to the point where we actually knew how to do it, and at that point we raised some money from some angel funders, and made a company called Applied Proteomics, which has worked out how to do this, and built this assembly line which does these hundreds of steps, and measures along the way, and does it in an automated way. For the first time, the results are accurate and repeatable. When we test the same sample, we get the same result.
You can take a drop of blood, and get a repeatable measurement over a hundred thousand repeatable stable features. We don't know necessarily what all of them are, but many thousands of them we can identify as known proteins, and we now have genes associated with them. Often that means we know something about the function, or where they are created in the body, or something like that.
Let me show you the results of that process, which is on this slide.

Figure 1: Differential Feature
This is actually a small part of the measure that we get out of a drop of blood; this is actually a small part of a bigger picture. We've spread out the fragments of proteins in two dimensions here. It's a little bit analogous to a gel that you might see, or a gene chip, the same protein feature will always appear in the same position every time. The brightness shows how much of that protein there is. This display actually doesn't show you too much of the dynamic range and brightness, but we are measuring that.
In the horizontal direction we're measuring the mass of the protein fragment. The vertical axis is how slippery it is. People have produced pictures like this before, but what's interesting here is that every time you do this, the features come out in exactly the same places. That hasn't been true before.
Just to show you how precise these pictures are, you notice that these things tend to occur in these little groups of stripes, tick, tick, tick. You see there are several of them in each group, and they kind of trail off; it's almost like a ring, or an echo. Well, the reason for that is that carbon has different isotopes, and so if there is an extra neutron, you have a different isotope of carbon in the protein, then it's going to be slightly heavier. That distance between the stripes is actually the weight of one neutron; it gives you an idea of how precisely we're measuring things. There's nothing in between because there's no such thing as half a neutron. In fact, measuring things so precisely we can often tell by the shape, how many carbon atoms there are in the protein.
Figure 2: Yellow Overlay
The amazing thing about this picture is I'm actually showing you two measurements of two different blood samples on top of each other. One of them is shown in red, and one of them is in green. Things look yellow because the two are exactly on top each other, because the two blood samples are mostly the same. But, if I look closely at this ... actually let me just find a spot which is different ... okay, well, actually here is a good spot. There is some protein that was in one of the blood samples that wasn't in the other one, so you only see it as the green. There is another place where you see there's a little red down there. That is something that is in one sample and not the other.
It's almost as though we've got a digital read-out of this highly analog process. That's the amazing sort of engineering feat that I don't believe anyone else has achieved that kind of repeatable precision over that much range before. What we know is the relative concentration of each of those proteins. Now, this pair of tests might be the same person at two different times, or it might be two different people. They probably both have the gene to produce that protein, but for some reason one of them is saying this, and the other one isn't saying this at this time.
Now if we have a hundred thousand of these features — and we do have more than a hundred thousand — then the question goes on to what do they mean, what do we do with it? That's the stage that we're at now. It may be that some of those like a genetic test, maybe a single feature will actually tell us something. But probably much more of the information is in the patterns and combinations, and so on.
For instance, let's say that we go to cancer patients, and we try out a drug on them, and we find out that only 10 percent of them respond to the drug. It would be very nice, if there were some genetic marker that told us which 10 percent responded to the drug, because it's a miracle drug for those 10 percent, but it's a useless drug if only 10 percent of the people respond to it, and it makes 20 percent of the people sick. You would like to know which are which, and it was a great hope that maybe you would be able to find genetic markers to do that. There are a few drugs that that's true for, but by and large, that information doesn't seem to be just in the vocabulary list.
But the information is much more likely to be in here, there's something dynamically happening, and so if we can start to say, "If we see this pattern approaching expression, it means that you've got this thing going on metabolically." All of a sudden we've got hundreds of thousands of symptoms to look at, if you will, or hundreds of thousands of indicators of what is going on at the level of what's actually going on.
In the process, I started looking at how we treat cancer, and how we think about cancer. This is another area where I think there's a wrong paradigm that has gotten started because there's been a great success, and that success has been over generalized. In this case the great success has been the treatment infectious diseases and the germ theory of disease. This is the greatest success of a theory in medicine.
That was a very cool development, because if you can figure out what species of germ you were infected with, then that sets how you should treat the disease. You could treat the disease with something that would kill that germ. That became the general paradigm of medicine. You would do a diagnosis, a differential diagnosis to figure out what the infectious agent was, and then you would apply a treatment that was very specific for that agent.
That's the thing that doctors are basically trying to do, identify the disease, and treat the diagnosis according to the best method. That allows science to come in because you can objectively test whether a particular treatment is effective, or not effective, when dealing with that diagnosis. Does quinine help the symptoms of malaria? Is penicillin the best way to treat anthrax? Once you know what's best, that's the thing that doctors are taught to do.
Interestingly enough, that way of looking at things is not the only one in the history of medicine. Historically, doctors had theories that are today more like Ayurvedic medicine, with its emphasis on balances between various forces in the body. Or in the West, a medieval doctor might have tried to make you less choleric or more phlegmatic. The idea was to try to restore the order of the various forces that were controlling the body. It's interesting, at the time that the germ theory of disease was really exploding, and antibiotics were being discovered, J.B.S. Haldane said, "This is a disaster for medicine because we're going to get focused on these germs, and we're going to forget about the system." He was right.
Indeed, if you look at what happened, it was a disaster for treating diseases like cancer because we started thinking of them almost like they're infectious diseases. It's a habit of thought, so when a patient comes in, we diagnose them, and we put them in a category, and then we try to apply the treatment that is shown to work on that category. We do a blind clinical trial of how people that are in that category respond to a certain drug. That makes a lot of sense for infectious diseases because infections are species, they speciate, and divide out, so putting them in categories makes a huge amount of sense.
But a systems disease like cancer, or an auto-immune disease, is a break down in the system, much more like a program bug. We would never think of debugging a computer by putting it into one of twelve categories, and doing something based on the category. Actually we do, it is kind of "help-desk debugging" that doesn't work very well in complex situations.
There is a big difference between help-desk programming debugging, and the kind of debugging a programmer really does when they're trying to more subtly fix a program.
What we've got in medicine now is kind of help-desk debugging. We put you into a category. In cancer we start by putting it in a category that's based on the part of the body where symptoms of the cancer have been shown. Then we test drugs that way: Does this drug work on lung cancer, and if it does, well, it's not approved for prostate cancer because we tested it on lung cancer. That's a whole other experiment, that's a different category of disease. Then we subcategorize them. We take a biopsy sample, and we say, "Well, these cells are kind of squishy and long, and those are kind of round, so we have the squishy, long cancer, and the round cancer." We declare that we have two forms of breast cancer.
We keep coming up with more kinds of cancer as we measure more things, and then we subdivide the categories. There used to be dozens of kinds of cancer, and now there are hundreds of kinds of cancer. But I actually think there are millions or billions of kinds of cancer. Cancer is a failure of the system. Happy families are all alike, but unhappy families are all unhappy in their own special way, and happy bodies are kind of all alike, but when they break down, they all break down in their own special ways.
The breaking down is at the level of this conversation that's going on between the cells, that somehow the cells are deciding to divide when they shouldn't, not telling each other to die, or telling each other to make blood vessels when they shouldn't, or telling each other lies. Somehow all the regulation that is supposed to happen in this conversation is broken. Cancer is a symptom of that being broken, and so when we see a whole bunch of cells starting to divide uncontrollably in an area, we call that "cancer", and depending on the area, we'll call it "lung cancer", or "brain cancer". But that's not actually what's wrong, that's a symptom of what's wrong.
To use another kind of analogy, let's say we didn't understand anything about plumbing, but occasionally we came home and our living room is filling up with water, and sometimes we come home, the kitchen is filling up with water, and so we start describing the problem as, "Well, my house has water, that's the problem." We might even divide it and say, "My house has kitchen water, or my house has living room water." If plumbers were like doctors the best they might be able to say is "we've learned about kitchen water, and if we pour a lot of drano in the kitchen, then kitchen water sometimes goes away. Living room water is fixed by pouring a lot of tar on the roof." Indeed, there might be ways of fixing the problem, but what you really need is to understand about plumbing. You should be worried about the process that's creating the water, and understanding about what's supposed to be draining, and what's supposed to be holding it, and so on.
In fact, we misunderstand cancer by making it a noun. Instead of saying, "You know, my house has water", we say, "My plumbing is leaking." Instead of saying, "Somebody has cancer", we should say, "They're cancering." The truth of the matter is we're probably cancering all the time, and our body is checking it in various ways, so we're not cancering out of control. Probably every house has a few leaky faucets, but it doesn't matter much because there are processes that are mitigating that, by draining away the leaks. Cancer is probably something like that.
In order to understand what's actually going on, we have to look at the level of the things that are actually happening, and that level is proteomics. Now that we can actually measure that conversation between the parts, then we're going to start building up a model that's a cause-and-effect model: This signal causes this to happen, that causes that to happen. Maybe we will not understand to the level of the molecular mechanism but we can have a kind of cause-and-effect picture of the process. More like we do in sociology or economics."
Whatever the treatment of cancer, or auto-immune disease, neurodegenerative disease or other system diseases will be like in the future, there won't be a diagnosis step, or at least that's not what will determine your treatment. Instead, what we'll do is we'll go in, we'll measure you by imaging techniques, and taking it off of your blood, looking at the proteins, things like that, build a model of your state, have a model of how your state progresses, and we'll do it more like global climate modeling.
We'll build a model of you just like we build a climate model of the globe, and it will be a multi-scale, multi-level model. Just as a global climate model has models of the oceans, and the clouds, the CO2 emissions, and the uptake of plants and things like that, this model will have models of lots of complicated processes happening at lots of different scales, and the state variables of this model will be by and large the proteins that are moving back and forth, sending the signals between these things.
There will be other things, too. But most of the information is in the proteins. There will be a dynamic time model of how these things are signaling each other, and what's being up-regulated, and down-regulated, and so on. Then, we will actually simulate that under lots of different treatment scenarios; we'll simulate for your cancering, how we can tweak it back into a healthy state, having it guided back toward a healthy state. It will be a treatment that's very specific. We'll look at those and see which ones are most likely to bring you to a healthy state, and we'll start doing that, and we may treat you in a very different way than we've ever treated any other human before, but the model will say that for you that's the correct sequence to treat it.
Right now this would be a huge change in medicine. For instance, the way we pay for medicine is dependent on the diagnosis. You pay a certain amount for prostate cancer, and you pay a different amount for lung cancer. That determines what part of the hospital you get routed to, which doctor sees you, what the insurance company will pay for. If you take that out of the system right now, it's a completely different kind of a system. I don't think this will be an easy switch and I don't know what the sociological/economic processes will be. But it will happen because it will start working better.
It will probably happen first with desperate people who aren't getting fixed with the normal methods, will go to this alternate process, and when enough of them start getting fixed by this alternate process, then that will, by some complex sequence that I won't even try to predict, eventually change medicine.
Of course there is a lot to be done to make this work. We are dealing with very different time scales and different space scales, too. There are useful things that are hour-to-hour time scale, in your bloodstream, and your cell level is probably more like minute-to-minute, or even faster. Right now we're just beginning to be able to measure proteomics within a single cell, and so right now what we are doing with the National Cancer Institute is trying to bring all of those time scales, and space scales together into a model. This is probably, with today's technology, a ridiculous stretch, but we're at least attempting to do it.
We're measuring things both at the inside the cell level, measuring at gene expression the production of proteins, the placement of proteins within the cell, then the conversation between the cells. That we're trying to do at more the minutes time scale, and then we're doing what's happening in the body and the blood, on the days time scale. We should be probably measuring it over hours, but with current technology we can't afford to do that.
We're doing this in mice right now, but we can only draw so much blood from a mouse. Those kinds of things are limiting us. We're also doing it with imaging, the actual geometry of the tumors, so we're actually trying to measure geometry; we're trying to measure the genetic evolution of the tumor because the tumor is not homogeneous. Genetically it's different inside than outside, and we are trying to make a model, like one of those kind of global climate models, for lymphoma in mice. We can get genetically identical mice, and we can actually very reliably give them the same kind of lymphoma, and so we can repeat the experiments.
So it's much better than the global climate models situation. With global climate, we have one experiment to calibrate our model, and we're in the middle of it. There is no control. In the mice we can do a lot, we can try different variables, and then also try what are the effect of different things that we can do in terms of treatments, of giving chemotherapy of various sorts, or heating them up, changing the pH of their blood, doing all kinds of things like that, and begin to get a perturbation model of not just how the system normally works, but how it works under different kinds of perturbations. Then hopefully, eventually, we'll get to the point where we have a good enough model that we can actually predict: if we do this to this mouse we can actually make it live longer.
We are already learning a lot. One is, for this mouse study, we're combining some new techniques like proteomic techniques with a lot of techniques that were developed for other reasons, for instance imaging techniques that are very detailed. We're actually putting little windows into the mouse, and watching the tumor grow, and then we can use things that have antibodies that bind to certain kinds of proteins that are being expressed, and so we can actually see where those proteins are being expressed in the living mouse, so see geometrically where they're being expressed.
There are techniques, for instance, where we can actually look within a cell, and see where a protein is within the cell. We can actually do microscopy below the wavelength of light now, which is a fantastic advance, by using basically little flashes of light, and computing on top of it. There are huge advances in the technique and instrumentation and so on that's making this at least conceivable for the first time. It's only a matter of time before it will be possible, and it's quite probable that this first attempt is too early, but we are attempting to do this with the consortium of people in places like Stanford, and Cold Spring Harbor, and USC, UT, NYU and Caltech. The National Cancer Institute, has actually given our group five years of funding, assuming we keep making progress.
They had this crazy idea of getting people like me, who are not really biologists, to be the principal investigators of these centers, to work with clinicians to design the program of research, which is then being carried out by a lot of people who know things like how to put windows into mice, and how to image a tumor, or how to get antibodies to glow. So we're using all of those biological lab techniques to do something that's really more like a physical sciences model.
I'm optimistic that we'll have enough success that people will at least try to repeat this form of experiment. Whether we actually are able to make accurate predictions is yet to be seen. The group coup would be if we got to the point where we could say, "We can predict that if we do "this" to this mouse, then we can take care of "that" in the mouse". That would be success. But we can learn a lot without getting that far.
![]()
CANCERING: Listening In On The Body's Proteomic Conversation (PART II)
W. Daniel Hillis
What I've been talking about here is more analysis than construction. The genome is used to construct things, and I'm claiming it's not the best place for analysis of what's going on. Certainly there are times it is useful, but I don't think that's where most of the information is. In fact, in some sense, it is literally true that the information that's in proteomics tells you everything that was in the genome, everything useful that was in the genome. In a sense, the genome is redundant if you have the proteomics, that's theoretical though, because the genome is digital, and we actually have it. In many ways it's enabled proteomics. ...
Printable text file (Parts I & II)
(During this session Hillis was asked to comment on a number of specific topics:) CANCERING: Listening In On The Body's Proteomic Conversation (PART II)
W. Daniel Hillis
On the relationship between genomics and proteomic testing
What I've been talking about here is more analysis than construction. The genome is used to construct things, and I'm claiming it's not the best place for analysis of what's going on. Certainly there are times it is useful, but I don't think that's where most of the information is. In fact, it is literally true that the information that's in proteomics tells you everything that was in the genome, everything that was useful. In a sense, the genome is redundant if you have the proteomics. That's theoretical though, because the genome is digital, and we actually have it. In many ways it's enabled proteomics.
Right now, when I show you that image that has the hundreds of thousands of dots on it, I can actually tell you what a lot of those things are because we know the genome; so I can actually associate many of those dots with genes, and because we have these great genetic expression tools and so on, we may know what part of the body it's in, we may know a lot about the pathways because we can do knock-out genes. It's a great experimental method for actually controlling what proteins get produced and so on. In many ways proteomics was made possible by genomics. It builds on top of genomics. I guess it's true in some theoretical sense that eventually you might not even bother to look at the genome if you can see the whole proteome. In practice, it's been very important.
The genome is the instructions for the cell. That's very important if you want to do manipulation. If you want to actually affect the pathway, then that is the level at which you need to manipulate things. You want to knock out a gene, or modify a gene. Experimentally, being able to read and write the genome is incredibly important. But if you want to use it as a diagnostic for what's going wrong with a particular individual, it will be unusual for that information to be in the genome.
On the role of gene testing in cancer
Let's take somebody who has cancer. They used to be somebody who didn't have cancer, and they had the same genome. So the difference between having cancer and not having cancer is clearly not just in the genome. There's more to it than that. In fact, most of their cells aren't cancering, and they have the same genome. Cancer is a dynamic process that's happening, and it's not just in the genome. Now, there may be a specific mutation from a genome that helps explain why it happened. For instance, one of the dramatic genetic test successes has been in breast cancer, BRCA1 and 2, which are specific genes that are associated with breast cancer. They occur a lot in Ashkenazi Jews, and a particular kind of breast cancer is associated with these genes. There are many examples like this where there's a genetic predisposition to cancer, but is one of the clearest examples. The cancer isn't inherited, but that's a predisposition that is, so people that have the gene are more likely to have cancer.
Let me put it in terms of the conversational analogy. That means that certain words are missing, and in that case we know there is a conversation about fixing broken DNA. We're repairing broken DNA and it's hard to describe what to do without those words. You need to discuss BRCA1 and BRCA2, and you need to use those concepts. You need to use those words in order to repair DNA in a certain way. If you don't have those words in your vocabulary, then you're unable to execute this process of repairing DNA.
If those words are slightly mutated so that they're not understandable, if you slur them, or stutter them or something like that, they're won't have the desired effect. It won't always cause a problem because there may be other pathways that also repair the same defect. If the other pathways are working very well to control your DNA, it might not matter. But there is an association, and you can look at people, you can test them, and you can say, "Well, if they have this mutation, they're more likely to get breast cancer", and actually, it turns out, they are much more likely to get breast cancer.
Furthermore, you know what the failure mechanism is, so there are many people who get breast cancer for completely different reasons that have perfectly intact BRCA1 and BRCA2. By the way, that same pathway, because it's a general pathway for repairing DNA, is also important for ovarian cancer because if you don't repair properly, then you're more likely to get ovarian cancer, too. It doesn't really have anything much to do with breasts other than that's where you see the symptoms of this happening, it's usually first noticed in breasts.
On the application of proteomic modeling to cancer treatment
The cancering metaphor does mess up our standard model of medicine, where we just take the right pill to fix a given problem. But if you think about it, the idea that you should be able to take a pill, and it should magically fix a disease, a systems disease, a failure of the system, is kind of amazing that that's even possible. The cases where it's mostly possible is where you have an invading thing that doesn't belong, like an infectious disease, and you take a pill that poisons that particular thing, like an antibiotic. There are a few cases where you're just missing one component, and you take a pill that provides the missing ingredient, and so there will be a few magic cases like that, but those are very special kinds of failure, and I don't think they'll be the typical failure in cancer.
Unfortunately this whole idea of fixing a disease with a pill, while it's delightful when it works, is not very generalizable. We haven't found very many new pills lately that really cure diseases. In fact, the pharmaceutical industry is kind of broken right now because they've run out of this low-hanging fruit, a magical chemical that cures a disease. I don't think we're likely to find a lot of more those. They need a different model.
The first commercial application of proteomics will be diagnostics and probably something much simpler than what I was describing before. The way proteomics will get started is by being markers for diseases that we already diagnosed, in other words, it will help support this categorization system of diagnosis.
Let's say I could find a pattern of proteins expressed in your blood that said whether your colon was growing polyps in it. That would be much better than having a colonoscopy. You get a colonoscopy every five or ten years, which is now recommended — even though in one in a thousand people they create serious damage giving the colonoscopy — we still recommend that people do it because we don't have a better way of telling if you're in this kind of precancerous stage. If you could do that in your annual blood test, it would be much better. That is an example of a very early use of proteomics. Probably there would be many things like that where if you could detect breast cancer without a mammogram, or if you could do a confirmatory test of prostate cancer without doing a needle biopsy, all of these things are very invasive, and expensive, and cause a lot of secondary harm to people.
On the relationship between proteomics and synthetic genomics
At last year's Edge Master Class in Los Angeles, George Church and Craig Venter talked about Synthetic Genomics. Proteomics is relevant to that because it's also a tool that such researchers could use since they need to debug their synthetic genomics. When you write a computer program, the first thing you do is you try to run it, and it almost always has a bug in it, so you see what happens, and you debug it, you stop it in the middle of running, and you see what the state of the system is, and you understand what your bug is, and then you change the program.
Right now George and Craig don't have the debugger. Proteomics is the debugger that they need. When they write a program and it doesn't work, which actually happens a lot, in order to tell why it's not working, they need proteomics to say, "Oh, I see, this isn't upregulating that enough, or downregulating that ... ", and that will help them debug their program and tune their program. Right now a lot of synthetic genomics is about copying a naturally-evolved program, and saying, "Okay, I can make a copy of this program, and write it, and it does the same thing", and that's interesting. It would have been very surprising if it hadn't worked.
On the business of proteomics
The business of proteomics had a false start a few years ago. As I said, proteomics can't be done with the techniques and tools that are sitting around a laboratory, a biological laboratory; it's not a biology problem. Unfortunately there are a lot of people who tried to do it with those tools and so there were a few companies that started up, and a lot of laboratory projects that started up, and they published a bunch of results probably prematurely, and they couldn't replicate them because, you know, the next time they ran the tests it came out differently. It was so noisy that they had to do very, very large trials. So if you have a bad instrument, then it's not going to work.
Because of that, proteomics got a bad name among the venture capitalists. Probably most venture capitalists will cut and run if you say "proteomics" right now because of the problems with the tools of a few years ago. What will happen is we'll get some successes. In spite of this, there will be a few things like Applied Proteomics that get started, and there will be a few people with more vision that look at it more closely, and say, "This actually fixes the problem that they had before, because the story was right before, it was just they couldn't make it work." As soon as there is a success, then you'll see a general change in attitude. Venture capital tends to work this way. There will be lots of people investing in this area, and there will be a boom very much like there was in genomics, and sequencing. Lots of effort will go into both the technology of doing the proteomics better, as it happened with genomics, and also the application of proteomics.
And again, first it will be to these diagnostics, and then it will be things like drug rescue. Billion-dollar drugs that had to be taken off the market after having had huge amounts of money invested in them because one in ten thousand people reacted badly to them. Well, if you could tell who was going to have that reaction, if you could make a test for it, and again, if you could find in a proteomic marker for what it was about, what was wrong with the dynamics of their body to cause them to have that reaction, then all of a sudden such drugs would be viable again. They could recover that billion-dollar investment. You'll see pharmaceutical companies take it up for reasons like that. That's the "safe" part pharma companies are looking for drugs that are "safe and effective", so it will help them with safe.
It will also help them with "effective" because right now, if you have something that not everybody responds to then it is not effective. We've had the first examples of that already, where a drug wasn't statistically effective. But when we look again we can say, "Well, people who have this protein being expressed, it is effective." So there is a very simple case where you're looking at a single protein. This single-protein expression is a situation analogous to a conversation with somebody shouting "Fire". A single protein is a very degenerate case of the conversation. There will be a few markers like that, that are simple markers, but mostly I think we'll look at things that are much more complex patterns that happen in multiple proteins.
Dosage is another reason why pharma companies will get very interested in proteomics, and it probably will make a big difference in research. Right now you can't tell what's happening until it gets all the way up to having a symptom in a patient. If you have something that takes a long time to play out, like Alzheimer's disease, or ALS, you really don't know if your drug is doing any good for years and years. You have no idea if the dosage is too high, or the dosage is correct. The feedback loop is very, very indirect, and lots of other things are affecting it, too. But if you could actually look at the proteins and notice this bad problem of communication between the cells, that's causing plaque formation in the brain in the case of Alzheimer's, then you might be able to see the response of the drug immediately, even though the symptoms aren't changing yet. The symptoms may take years to change, but you can see the drug is effective in this patient immediately… or that it is not, so you can move on to trying the next drug.
You could titrate the dose and very quickly say. You can titrate the dose not only so the guessing holds the correct, safe dose, but actually specifically for the patient. We know that people respond very differently to drugs. Right now it's a trial and error process. They give you a little bit, if that doesn't work they give you more. We see this happening even with simple drugs like blood pressure drugs. Now, with blood pressure, doctors can measure blood pressure easily. They should give you a small dose of the drug first, they see if your blood pressure went down enough, and they can give you a little bit bigger dose. You can do that as a quick loop and you calibrate the response for an individual because you can measure blood pressure. Well, you can't do that for something where the outcome is years away. Proteomics ought to let us do that, too.
On the way proteomics will change treatment
Something that I skipped over in describing the new treatment paradigm, and the simulation paradigm of treating rather than the diagnosis paradigm, is that right now what you do is you diagnose, and you select a course of treatment. Now, what really happens if it doesn't work, maybe you switch and jump on to a different track. But the interesting thing, once you can kind of measure the dynamic state variables, is you're constantly redoing that. You replan every time you go into the doctor. There is not a notion of staying the course, there's no reason to stay the course because you can tell you're getting closer. You redesign a new treatment every time you remeasure. You're constantly getting feedback. You don't just design a special customized treatment per person, you do it per person per time, per person per visit to the doctor.
What you're trying to do is guide it back to a healthy state, basically. But the other great thing is because you're looking at the whole state, you're not just treating one thing at once. That's the other thing that's a flaw in this idea we've gotten about medicine, which is in the infectious disease model. The fact that you have malaria is the main event. You've got to kill off that malaria before anything else can happen. But in the systems diseases, there's lots going on in the body, constantly. So when we say a treatment is safe and effective, the way that we test that is we're testing one thing at once, not looking at everything else. So we say, "Okay, well, some statins lower your cholesterol, which we think is a surrogate for you're going to have a heart attack", so we give everybody a statin.
Now, if you look at some of the early monkey studies where they first studied statins, and proved that it lowered cholesterol, the monkeys that were taking the statin had a higher death rate than the monkeys that weren't taking it. What does that mean? Well, they kind of ignored it, because they looked at the deaths and they were from accidents, or getting into fights, things like that. I bet that it's going to turn out that statins actually cause you to get into fights, and have accidents. It will have effects on your mind that weren't studied in all the studies of statins, and in fact, statins may not be good for you. Or they may be good for you for reasons that have nothing to do with lowering cholesterol.
That's another thing that we're discovering in statins. The idea that we go in there, and we have this very complicated system, and pick one variable and say, "Does this one variable get better when we give this person this pill?", and then say, "Okay, well, it did." The engine rate went up because we poured this goop into the engine. But is that really good? Well, maybe the speed went up because it broke the regulator or because it clogged up the safety valve. So right now when we test the drug, we're looking at one thing at once. We only discover these bad side effects in these retrospective studies looking back after people have been taking the drug for a long time. ?
What most of these drugs do is shift the balance. They're trade-offs. There is a reason why you don't naturally produce statins. I don't think it's because nature didn't think of the idea, it's probably because statins have some pluses and minuses, and so what you're doing is you're rebalancing things, tipping things in a certain direction. The reason that's relevant is if you're in the paradigm of diagnose the disease, treat the disease, then that tends toward treating the disease at the cost of making everything else a little worse, than if you're looking at the whole system, and trying to optimize the whole system. Proteomics is looking much more at the whole system.
Proteomics can also tell you things that can give some substance to what nutritionists have been talking about. If you look at traditional Chinese medicine, or Ayurvedic medicine and things like that, it's all in terms of balances, restoring this force against that force, but it doesn't have a very good model. It is a highly oversimplified model that's been made up without much scientific information going on, just a lot of time going into it. If you had a much better model, then you could probably rationally understand what foods you should really eat that bring your body back into balance.
It is probably very different for different people, and so I don't think the treatment is necessarily going to be taking a pill. You will take pills, but you'll also change diets, or you may discover that it's very important for you not to be stressed out in the afternoon, you may find it's important for you to get lots of oxygen, or do something very aerobic. You may find out that you better not get cold. Or we may deliberately heat you up to an abnormal amount for a little while. Maybe you will need sequences of these things. I don't think treatments will be "a thing", like a pill, I think treatments will be perturbations, bringing you toward health, with some feedback as to what results all those perturbations are having.
In a sense we already have home proteomic tests. Some of these home pregnancy tests may be that. What's happened is, for various reasons, we have luckily discovered certain proteins that are diagnostic, PSA is a great example.
PSA is a protein, a prostate-specific antigen, and for various reasons we happened to notice that this was a marker for prostate cancer, that it was associated with prostate cancer. Now when you go get a blood test, if you're male you probably automatically get a PSA test. That is a protein test — a test for a specific protein. Once you can look at the whole protein, one of the things that will happen early is you'll identify specific proteins to test for, and those may be home tests. They may be finger prick tests, or there may even be indicators of a protein that are excreted in your urine, so it wouldn't surprise me at all if you get home tests that come out that were identified by looking at the whole proteome. But my guess is, again, those are going to be kind of unusual, special cases.
In some sense it's really lucky that there happens to be a single protein that's associated with inflammation in the prostate. In fact, maybe it's lucky, maybe it's not, because there are a lot of people getting needles stuck in them unnecessarily because of this test, and probably they would be much happier not being told they have prostate cancer, because it probably won't hurt them anyway. Maybe the needles are worse than what would have happened without the test. It causes a lot of worry, and stress, and maybe the stress even makes them prone to some other kind of cancer.
Probably there is a much more sophisticated combination of lots of different proteins that you can look at and say, "This is an inflammation of the prostate that's actually not cancer." Or, "This is an inflammation that looks like this particular kind of cancer that responds to this drug, while this is a particular kind of cancer that grows very slowly, and it's not going to kill you. You'll die of something else first, so you don't need to worry about it." Once we get much more subtle measures, once we can listen to that conversation and find out what's actually going on, then I think there will be a lot less treatment. We do a lot of overtreating of things, and a lot of damage by treatments. That's actually one of the only things that can actually reduce the cost of medical care. The cost of medical care is mostly way down the line when people at hospitals, are already pretty damaged by disease and treatment by the time they become very expensive.
If what you can do is spend more of the money up front diagnosing things, tweaking things before it gets to that stage, then that is a win-win because it's better for the patient to get less treatment, and better for the insurance company because you never get to the hospital. Of course, the doctors actually are happy because they really do want to cure the patient. They have more tools to actually know what's going on. It's very frustrating for the doctors to know that a treatment might not work.
Doctors hate this thing of giving you a sequence of poisons: hopefully we'll kill the cancer faster than it will kill you. That's a horrible thing to do to a patient. I think oncologists would love to have better ideas of what the effects of the treatments that they're giving are, and is it actually doing any good. They want to avoid giving people treatments that are not going to help, that are going to make them sick.
On home testing
I'm sure we'll have examples where people can do self-testing, perhaps for a single protein. I think it's going to be rare cases. Sometime we may see proteins or parts of them in the urine. Mostly proteins get broken down, unless you have something like bladder cancer.
Usually we test the blood. But, diabetics do blood draws all the time at home, and tests. So I can certainly imagine things that are the equivalent of diabetic sugar meters, glucose meters that you're adjusting your own dose of blood pressure medication, or anti-cancer medication, or something like that. Right now proteomics makes it very expensive to do because we're just able to do it for the first time. But certainly once you've identified what you're looking for, then there is some fairly standard methods of changing that, and turning that into tests that are very easy. The classical method is you develop an antibody to the protein, and then you can make something that changes color. More and more it will be changes to the conductivity of a transistor so that you won't read out a color, you'll have a little machine that does the analysis, not just indicating presence or absence.
I think the interesting information will be in the levels of many different proteins. The picture I showed you was a protein that was produced in one and not in the other. Much more common, though, we see proteins that change in levels by 20 percent or something like that. A lot of the information isn't just on/off, it's in the concentration. You don't totally turn it on or off, you change the rate at which you're producing it and a lot of drugs basically do that, or they change the rate of production or destruction of something. They upregulate something, downregulate something else. If you take BRCA as an example, there's another protein that I think regulates a promoter of BRCA production, and actually if you have a mutation in that, too, then the mutation in BRCA is less important because it's not regulated. That's a completely different kind of subcategory of breast cancer.
When you try to downregulate something, it is because you have too much of it, so you lower it by giving a drug that suppresses its production or speeds up its destruction It's all in the quantities, it's not just present or absent like it is in the genome, and that's the thing that's really neat about the genome is it really is digital. You either have a gene, or you don't. You have this variant of the gene or you don't. You have one or two copies of it.
I'm emphasizing blood because it's nice you have a collecting system built into your body that goes around and touches every place in your body and collects fluids. It's very convenient for diagnostics. But there will probably be things that happen in tears, or in saliva, or in lymphatic fluid, or spinal fluid, but your body is plumbed very nicely for blood so that you can get it out easily, and since it delivers nutrients, and gets rid of waste, it pretty much is involved in anything very dramatic that's happening in the body. It's good low-hanging fruit, at least.
In diabetes treatment, what we do now is we basically get around your pancreas. Doing what your pancreas does by adding insulin. We try to mimic the pancreas. Proteomics may allow us to actually stop the processes that cause your pancreas to go bad earlier. We know that that's something that can be affected by diet. Again, it's probably predispositions, so if you're missing certain vocabulary words, it's harder for certain kinds of processes to work, and so you are particularly susceptible to certain kinds of problems, so that's where genetics comes out. Then proteomics can see, are you actually having those problems that you're susceptible to, or are your other redundant mechanisms taking up the slack for it? The body seems to be highly redundant, and often has lots of mechanisms for doing anything important.
On redundancy and treatment
Probably the biggest surprise that happened with genetics is once we had the ability to knock out genes, everyone thought, "This will be great, we'll knock out the gene and see what breaks." Well, it turns out mostly when you knock out a gene, at least half the time nothing seems to break. There was some redundant thing that just took up the slack. Probably if you did very careful studies on those knock-out mice you would find out that they were more susceptible to certain kinds of diseases or breakdowns because they're missing one of their redundant mechanisms.
It's interesting that evolved systems, much more than engineered systems, are evolved to be robust and redundant, and if you think about it, robustness is a kind of information hiding. What you wanted to do is you wanted to respond the same under many different kinds of circumstances, and with some of its parts broken. What you're doing is you're hiding the information in effect about, how it's working. The very process of making something robust is a process of hiding the information at the level of the symptoms, at the level the physician is looking at. In a very real sense, evolution has evolved your body to make the systems uninformative about what's going on inside.
It's kind of amazing that a doctor can look at things on the outside of you, and take your temperature, that it works at all that you can look at the outside of somebody and decide what you should do to them to make them better because evolution has evolved it for that not to work, in effect. It's actively hiding the symptoms of what it's doing, because that's what it's evolved to do, it's evolved to do the same thing no matter whether it's working or not in some sense, or whether each piece of it is working or not.
You do need to get to a different level to see what's going wrong. Mostly the body fixes itself when it's cancering, and so if you can just sort of help it, tilt it in the right direction, probably most cancers would fix themselves if you give them a chance to.
Oddly, though, if you think about that and think about chemotherapy, which is basically the strategy of let's try to poison the cancer, even though we poison you, it seem crazy. Let's try to have a poison that's just enough not to kill you, but to kill the cancer. Well, you're also probably compromising all those mechanisms that fight the cancer, rather than propping them up. In some sense we're probably making the body's job harder in our attempts to treat it.
Mainstream medicine tries to understand what are the mechanisms, what are the pathways, tries to design things that enhance, or block something bad from happening and so on. Proteomics is a new tool that gives you a whole lot more information to do that with, and once you have a whole lot more information, then that lets you do a much more informed dynamic intervention. It helps to give you insight in the actual works of the pathways. That's a very mainstream idea. I don't think anybody would argue with that.
On symbiosis
A really interesting point is that probably a lot of the system that is our healthy body actually doesn't have human DNA at all. It has some other microbial DNA, and we probably are a complicated ecosystem of different types of our own cells, and lots of non-human microbial cells. Once we start looking at the proteome, we'll be looking actually at the conversation of all of those cells, not just the human cells.
Some of those stripes that show up in the picture I showed, we can say, "Oh, that corresponds to this human gene." Some of them, we don't know they might be produced by some combination of other proteins, might be some other organism's protein. Microbial protein would show up in that too, or response to microbes. One of the beauties of this is that we see everything, whether it's of human origin or not. We actually can see it all in the proteome.
On the National Cancer Institute
The leaders of the National Cancer Institute are very keenly aware of how little progress has actually been made in the treatment of cancer. This is something they pay a lot of attention to. They're thinking very laterally in giving funding to people like me to work on cancer. What they've done is to say 'Let's bring in some new kind of thinking to this, and let's have a program where we have physical scientists be the principle investigators, partnered with the co-investigators who are clinicians and biological scientists. I'm partnering with David Agus, for example. But giving money to the physical scientist is a pretty radical idea; you can imagine it is very controversial within the biological community. NCI has started start a few of these centers, and given them five years to work. They need to be interdisciplinary and geographically distributed.
Our center at USC has people all over the United States involved in it, like Cold Spring Harbor, Stanford, Arizona, UT, NYU and Caltech. Typically these labs will have a particular technique for studying biology. It might be measuring proteins within a single cell, or imaging the growth of a tumor. Very often these things are very, very hard to do, and so people have built their career on a new way of sensing proteins inside the cells, and they have teams of graduate students who are refining this technique, and doing variations of this technique, and developing it and so on.
There is about a dozen of these physical sciences centers, each of them is the same kind of structure, there is a physical scientist who is paired with an oncologist, and a group of people that are geographically distributed, applying their techniques to a program of research. In our particular program of research, as I've described, we're trying to take one cancer, study it with all these different techniques, and build a model of how it develops. Different centers have different goals for what they do, but what they all have in common is somebody who is not a biologist trying to use the tools of biology to study cancer in some way.
The proposals for these centers got reviewed by a peer review process, with biologists evaluating at them. One of the reasons that the biologists liked our program was that, surprisingly enough, it's really unusual, even unique for somebody to take one line of cancer and study the same line of cancer with all of these different tools. Typically what people do is study a different cancer with a different tool, and they find the cancer, the type of cells that they can grow in that lab that works well with their tool. The idea of picking a few different specific cell lines, and studying them from a lot of different dimensions, and lots of different scales; I believe that, our proposal probably got funded because the biologists said, "That's going to be useful even though we don't believe this modeling stuff will ever work. Just doing that will be very useful."
A lot of the resources that have been put into cancer have generated the preconditions so that we can do this. I don't feel those resources were wasted in any way. We really understand a huge amount about pathways, and specific mechanisms, so we know a whole lot more about cancer, even though we can't treat it much better in many cases. We have a lot more information, and that information can be made more useful now that we have this proteomic information. This isn't in the category of throw away everything we've done and start over, this is an incremental progress next step that's built on top of an incredible mountain of work.
On how these efforts could fail
There are a couple of ways that I could be wrong, or fail. The timing could be wrong. It could be that we don't have enough of that information built up about the mechanism to interpret these results yet, so it could be that when we really started analyzing we just failed to find the patterns of proteins that correlate with useful things to treat. I would bet then that that's probably just an issue of timing. We're too early, we don't have the right information to bring together with it, or maybe we're not doing the measurement in enough detail.
Maybe it's not these 20 percent changes, maybe it's 2 percent changes, or maybe it's changes in much rarer proteins that we're not measuring by this method, something like that. Maybe it's not in the blood. Maybe most of the information stayed inside the cell. Maybe the action is happening within the cell, not between cells, in which case, probably it will be much longer before it's diagnostically useful in medicine.
Eventually, almost certainly, it will be right. Whether, the timing is right to actually apply this information to medicine in the near future is a risky proposition, and the answer is probably they'll be partially right. There will be some things you can apply it to, and some things that remain mysteries until you look at much more detail of what's going on within each cell, or something like that.
Certainly there are other kinds of molecules that are important, too. It's not just proteins. We know, for example, glucose is important. There are small molecules that are important. Now, most of the small molecules, their production, breakdown, are regulated by proteins, so I'm guessing that if you have all the proteins' state, then you can infer what's going on with the other stuff. But there is state in the body in other things besides proteins. But most of the information seems to be in the proteins.
The body has lots of mechanisms for not only transmitting these proteins, but listening to them. If you look at what these molecular machines do, they talk to each other through these proteins; they say, "If you turn on, produce more of that, or less of that". They're measuring these proteins all the time, and responding to them. That's how your body works, that's how the feedback loops work. Your body is doing proteomics constantly.
It's exciting because for the first time we're really looking at the variables of this complex process, the dynamic variables, which is what life is. That may be too complex for us to comprehend, but at least we're listening in on the conversation. Whether we can understand it or not, we'll start learning in the next few years.
Master Classes
Event Date: [ 7.24.09 ]
Location:
Sunset Blvd
West Hollywood, CA 90069
United States


































Edge Master Class
Edge Master Class
Thomas Kalil
Thomas Kalil
France and Richard H Thaler
France and Richard H Thaler
Sean Parker, Thomas Kalil
Sean Parker, Thomas Kalil
Craig Venter
Craig Venter

![]()
On July 24, 2009, a small group of scientists, entrepreneurs, cultural impresarios and journalists that included architects of some of the leading transformative companies of our time (Microsoft, Google, Facebook, PayPal), arrived at the Andaz Hotel on Sunset Boulevard in West Hollywood, to be offered a glimpse, guided by George Church and Craig Venter, of a future far stranger than Mr. Huxley had been able to imagine in 1948.
In this future — whose underpinnings, as Drs. Church and Venter demonstrated, are here already — life as we know it is transformed not by the error catastrophe of radiation damage to our genetic processes, but by the far greater upheaval caused by discovering how to read genetic sequences directly into computers, where the code can be replicated exactly, manipulated freely, and translated back into living organisms by writing the other way. "We can program these cells as if they were an extension of the computer," George Church announced, and proceeded to explain just how much progress has already been made. ...
—George Dyson, from The Introduction
Edge Master Class 2009
George Church & J. Craig Venter
The Andaz, Los Angeles, CA, July 24-6, 2009
AN EDGE SPECIAL PROJECT
GEORGE CHURCH, Professor of Genetics at Harvard Medical School and Director, Center for Computational Genetics, and Science Advisor to 23 and Me, and J. CRAIG VENTER, Founder of Synthetic Genomics, Inc. and President of the J. Craig Venter Institute and the J. Craig Venter Science Foundation, taught the Edge Master Class 2009: "A Short Course In Synthetic Genomics" at The Andaz Hotel in West Hollywood, the weekend of July 24th-26th. On Saturday the 25th the class traveled by bus to Space X near LAX, where Sessions 1-4 were taught by George Church. On Sunday, the Class was held at The Andaz in West Hollywood. Craig Venter taught Session 5 and George Church taught Session 6. The topics covered over the course of a rigorous 2-day progam of six lectures included:
What is life, origins of life, in vitro synthetic life, mirror-life, metabolic engineering for hydrocarbons & pharmaceuticals, computational tools, electronic-biological interfaces, nanotech-molecular-manufacturing, biosensors, accelerated lab evolution, engineered personal stem cells, multi-virus-resistant cells, humanized-mice, bringing back extinct species, safety/security policy.
The entire Master Class is available in high quality HD Edge Video (about 6 hours).
The Edge Master Class 2009 advanced the themes and ideas presented in the historic Edge meeting "Life: What A Concept!" in August 2007.

GEORGE M. CHURCH is Professor of Genetics, Harvard Medical School; Director, Center for Computational Genetics; Science Advisor to 23andMe.
With degrees from Duke University in Chemistry and Zoology, he co-authored research on 3D-software & RNA structure with Sung-Hou Kim. His PhD from Harvard in Biochemistry & Molecular Biology with Wally Gilbert included the first direct genomic sequencing method in 1984; initiating the Human Genome Project then as a Research Scientist at newly-formed Biogen Inc. and a Monsanto Life Sciences Research Fellow at UCSF with Gail Martin.
He invented the broadly-applied concepts of molecular multiplexing and tags, homologous recombination methods, and array DNA synthesizers. Technology transfer of automated sequencing & software to Genome Therapeutics Corp. resulted in the first commercial genome sequence (the human pathogen, H. pylori, 1994). He has served in advisory roles for 12 journals (including Nature Molecular Systems Biology), 5 granting agencies and 24 biotech companies (e.g. recently founding Codon Devices and LS9). Current research focuses on integrating biosystems-modeling with the Personal Genome Project & synthetic biology.

J. CRAIG VENTER is regarded as one of the leading scientists of the 21st century for his invaluable contributions in genomic research, most notably for the first sequencing and analysis of the human genome published in 2001 and the most recent and most complete sequencing of his diploid human in genome in 2007. In addition to his role at SGI, he is founder and chairman of the J. Craig Venter Institute. He was in the news last week with the announcement that SGI had received a $600 million investment from ExxonMobil to develop biofuels from algea.
Venter was the founder of Human Genome Sciences, Diversa Corporation and Celera Genomics. He and his teams have sequenced more than 300 organisms including human, fruit fly, mouse, rat, and dog as well as numerous microorganisms and plants. He is the author of A Life Decoded, as well as more than 200 research articles and is among the most cited scientists in the world. He is the recipient of numerous honorary degrees, scientific awards and a member of many prestigious scientific organizations including the National Academy of Sciences.
INTRODUCTION: APE AND ESSENCE
By George Dyson
Sixty-one years ago Aldous Huxley published his lesser-known masterpiece, Ape and Essence, set in the Los Angeles of 2108. After a nuclear war (in the year 2008) devastates humanity's ability to reproduce high-fidelity copies of itself, a reversion to sub-human existence had been the result. A small group of scientists from New Zealand, spared from the catastrophe, arrives, a century later, to take notes. The story is presented, in keeping with the Hollywood location, in the form of a film script.
On July 24, 2009, a small group of scientists, entrepreneurs, cultural impresarios and journalists that included architects of the some of the leading transformative companies of our time (Microsoft, Google, Facebook, PayPal), arrived at the Andaz Hotel on Sunset Boulevard in West Hollywood, to be offered a glimpse, guided by George Church and Craig Venter, of a future far stranger than Mr. Huxley had been able to imagine in 1948.
In this future — whose underpinnings, as Drs. Church and Venter demonstrated, are here already— life as we know it is transformed not by the error catastrophe of radiation damage to our genetic processes, but by the far greater upheaval caused by discovering how to read genetic sequences directly into computers, where the code can be replicated exactly, manipulated freely, and translated back into living organisms by writing the other way. "We can program these cells as if they were an extension of the computer," George Church announced, and proceeded to explain just how much progress has already been made.
The first day's lectures took place at Elon Musk's SpaceX rocket laboratories — where the latest Merlin and Kestrel engines (built with the loving care devoted to finely-tuned musical instruments) are unchanged, in principle, from those that Theodore von Karman was building at the Jet Propulsion Laboratory in 1948. The technology of biology, however, has completely changed.
Approaching Beverly Hills along Sunset Boulevard from Santa Monica, the first indications that you are nearing the destination are people encamped at the side of the road announcing "Star Maps" for sale. Beverly Hills is a surprisingly diverse community of interwoven lives, families, and livelihoods, and a Star Map offers only a rough approximation of where a few select people have their homes.
Synthetic Genomics is still at the Star Map stage. But it is becoming Google Earth much faster than most people think.
GEORGE DYSON, a historian among futurists, is the author of Baidarka; Project Orion; and Darwin Among the Machines.

"For those seeking substance over sheen, the occasional videos released at Edge.org hit the mark. The Edge Foundation community is a circle, mainly scientists but also other academics, entrepreneurs, and cultural figures. ... Edge's long-form interview videos are a deep-dive into the daily lives and passions of its subjects, and their passions are presented without primers or apologies. The decidedly noncommercial nature of Edge's offerings, and the egghead imprimatur of the Edge community, lend its videos a refreshing air, making one wonder if broadcast television will ever offer half the off-kilter sparkle of their salon chatter." — Boston Globe
THE CLASS
Stewart Brand, Biologist, Long Now Foundation; Whole Earth Discipline
Larry Brilliant, M.D. Epidemiologist, Skoll Urgent Threats Fund
John Brockman, Publisher & Editor, Edge
Max Brockman, Literary Agent, Brockman, Inc.; What's Next: Dispatches on the Future of Science
Jason Calacanis, Internet Entrepreneur, Mahalo
George Dyson, Science Historian; Darwin Among the Machines
Jesse Dylan, Film-Maker, Form.tv, FreeForm.tv
Arie Emanuel, William Morris Endeavor Entertainment
Sam Harris, Neuroscientist, UCLA; The End of Faith
W. Daniel Hillis, Computer Scientist, Applied Minds; Pattern On The Stone
Thomas Kalil, Deputy Director for Policy for the White House Office of Science and Technology Policy and Senior Advisor for Science, Technology and Innovation for the National Economic Council
Salar Kamangar, Vice President, Product Management, Google
Lawrence Krauss, Physicist, Origins Initiative, ASU; Hiding In The Mirror
John Markoff, Journalist,The New York Times; What The Dormouse Said
Katinka Matson, Cofounder, Edge; Artist, katinkamatson.com
Elon Musk, Physicist, SpaceX; Tesla Motors
Nathan Myhrvold, Physicist, CEO, Intellectual Ventures, LLC, The Road Ahead
Tim O'Reilly, Founder, O'Reilly Media, O'Reilly Radar
Larry Page, CoFounder, Google
Lucy Page Southworth, Biomedical Informatics Researcher, Stanford
Sean Parker, The Founders Fund; CoFounder Napster & Facebook
Ryan Phelan, Founder, DNA Direct
Nick Pritzker, Hyatt Development Corporation
Ed Regis, Writer; What Is Life?
Terrence Sejnowski,Computational Neurobiologist, Salk; The Computational Brain
Maria Spiropulu, Physicist, Cern & Caltech
Victoria Stodden, Computational Legal Scholar, Yale Law School
Richard Thaler, Behavioral Economist, U. Chicago; Nudge
Craig Venter, Genomics Researcher; CEO, Synthetic Genomics; A Life Decoded
Nathan Wolfe, Biologist, Global Virus Forecasting Initiative
Alexandra Zukerman, Assistant Editor, Edge
SESSION 1 @ SPACEX [7.25.09]
Dreams & Nightmares [1:26]
SESSION 2 @ SPACEX [7.25.09]
Constructing Life from Chemicals [1:21]
SESSION 3 @ SPACEX [7.25.09]
Multi-enzyme, multi-drug, and multi-virus resistant life [1:06]
SESSION 4 @SPACEX [7.25.09]
Humans 2.0 [33.15]
SESSION 5 @ ANDAZ [7.26.09]
From Darwin to New Fuels (In A Very Short Time) [34:54]
SESSION 6 @ THE ANDAZ [7.26.09]
Engineering humans, pathogens and extinct species [40:35]
Thanks to Alex Miller and Tyler Crowley of Mahalo.com for shooting, editing, and posting the videos of the Edge Master Class 2009.
EDGE MASTER CLASS 2009 — PHOTO ALBUM
![]()
David Gross, Frank Schirrmacher, Lawrence Krauss, Denis Dutton, Tim O'Reilly, Ed Regis, Victoria Stodden, Jesse Dylan, George Dyson, Alexandra Zukerman
DAVID GROSS
Physicist, Director, Kavki Institute for Theoretical Physics, UCSB; Recipient 2004 Nobel Prize in Physics
"I should have accepted your invitation. I have been listening to the Master Class on the Web — fascinating. I am learning a lot and I wish I had been there. Thanks for the invite and thanks for putting up the videos. ... Invite me again..."
FRANK SCHIRRMACHER
Co-Publisher & Feuilleton Editor, Frankfurter Allgemeine Zeitung
I watched sessions 1 to 6. This is breathtaking. The Edge Master Class must have been spectacular and frightening. Now DNA and computers are reading each other without human intervention, without a human able to understand it. This is a milestone, and adds to the whole picture: we don't read, we will be read. What Edge has achieved collecting these great thinkers around is absolutley spectacular. Whenever I find an allusion to great writers or thinkers, I find out that they all are at Edge.
LAWRENCE KRAUSS
Physicist, Director, Origins Initiative, ASU; Author, Hiding In The Mirror
What struck me was the incredible power that is developing in bioinformatics and genomics, which so resembles the evolution in computer software and hardware over the past 30 years.
George Church's discussion of the acceleration of the Moore's law doubling time for genetic sequencing rates,, for example, was extraordinary, from 1.5 efoldings to close to 10 efoldings per year. When both George and Craig independently described their versions of the structure of the minimal genome appropriate for biological functioning and reproduction, I came away with the certainty that artificial lifeforms will be created within the next few years, and that they offered great hope for biologically induced solutions to physical problems, like potentially buildup of greenhouse gases.
At the same time, I came away feeling that the biological threats that come with this emerging knowledge and power are far greater than I had previously imagined, and this issue should be seriously addressed, to the extent it is possible. But ultimately I also came away with a more sober realization of the incredible complexity of the systems being manipulated, and how far we are from actually developing any sort of comprehensive understanding of the fundamental molecular basis of complex life. The simple animation demonstrated at the molecular level for Gene expression and replication demonstrated that the knowledge necessary to fully understand and reproduce biochemical activity in cells is daunting.
Two other comments: (1) was intrigued by the fact that the human genome has not been fully sequenced, in spite of the hype, and (2) was amazed at the available phase space for new discovery, especially in forms of microbial life on this planet, as demonstrated by Craig in his voyage around the world, skimming the surface, literally, of the ocean, and of course elsewhere in the universe, as alluded to by George.
Finally, I also began to think that structures on larger than molecular levels may be the key ones to understand for such things as memory, which make the possibilities for copying biological systems seem less like science fiction to me. George Church and I had an interesting discussion about this which piqued my interest, and I intend to follow this up.
DENIS DUTTON
Philosopher; Founder & Editor, Arts & Letters Daily; Author, The Art Instinct
Astonishing.
TIM O'REILLY
Founder, O'Reilly Media, O'Reilly Radar
George Church asked "Is life a qualitative or quantitative question?" Every revolution in science has come when we learn to measure and count rather than asking binary qualitative questions. Church didn't mention phlogiston, but it's what came to mind as a good analogy. Heat is not the presence or absence of some substance or quality, but rather a measurable characteristic of a complex thermodynamic system. Might not the same be true of life?
The measurement of self-replication as a continuum opens quantitative vistas. Here are a few tidbits from George Church and Craig Venter:
• The most minimal self-replicating system measured so far has 151 genes; bacteria and yeast about 4000; humans about 20,000.
• There are 12 possible amino acid bases (6 pairs); we ended up using 4 bases (2 pairs); other biological systems are possible.
• Humans are actually an ecology, not just an organism. The human microbiome: 23K human genes, 10K bacterial genes.
• Early estimates of the number of living organisms were limited to those that could be cultured in the laboratory; by sampling the DNA in water and soil, we have discovered that we undercounted by many orders of magnitude
• The biomass of bacteria deep in the earth is greater than the biomass of all visible plants and animals; ditto the biomass of ocean bacteria.
• The declining cost of gene sequencing is outpacing Moore's Law (1.5x/year): the number of base pairs sequenced per dollar is increasing at 10x per year.
Net: The current revolution in genomics and synthetic biology will be as profound as the emergence of modern chemistry and physics from medieval alchemy.
ED REGIS
Writer; What Is Life?
Almost fifteen years ago, in a profile of Leroy Hood, I quoted Bill Gates, who said: "The gene is by far the most sophisticated program around."
At the Edge Master Class last weekend I learned the extent to which we are now able to reprogram, rework, and essentially reinvent the gene. This gives us a degree of control over biological organisms — as well as synthetic ones — that was considered semi-science fictional in 1995. Back then scientists had genetically engineered E. coli bacteria to produce insulin. At the Edge event, by contrast, Craig Venter was talking about bacteria that could convert coal into methane gas and others that could produce jet fuel. It was merely a matter of doing the appropriate genomic engineering: by replacing the genome of one organism with that of another you could transform the old organism into something new and better.
George Church, for his part, described the prospect of synthetic organisms grown from mirror-image DNA; humanized mice, injected with human genes so that they would produce antibodies that the human body would not reject; and the possibility of resurrecting extinct species including the woolly mammoth and Neanderthal man.
But as far-out as these developments were, none of them was really surprising. After all, science and technology operate by systematically gaining knowledge of the world and then applying it intelligently. Thus we skip from miracle to miracle.
More extraordinary to me personally was the fact that the first day of the EDGE event was being held on the premises of a private rocket manufacturing facility in Los Angeles, SpaceX, which also builds Tesla electric vehicles, all under the leadership of Internet entrepreneur Elon Musk. The place was mildly unbelievable, even after having seen it with my own eyes. In the age of Big Science, where it is not uncommon for scientific papers to be written by forty or more coauthors, the reign of the individual is not yet dead.
VICTORIA STODDEN
Computational Legal Scholar, Yale Law School
Craig Venter posed the question whether it is possible to reconstruct life from its constituent parts. Although he's come close, he hasn't done it (yet?) and neither has anyone else. Aside from the intrinsic interest of the question, its pursuit seems to be changing biological research in two fundamental ways encapsulated Venter's own words:
We have these 20 millions genes. I view these as design components. We actually have software now for designing species, where we can try and put these components together. The biggest problem with engineering biology on first principles is that we don't know too many first principles. It's a minor problem! In fact, from doing this, if we build this robot that can make a million chromosomes a day, and a million transformations, and a million new species versions, it'll be the fastest way to establish what the first principles are, if we can track all that information and all the changes.
Unlike physics or more mathematical fields, research in biology traditionally hasn't been a search for underlying principles, or had the explicit goal of developing grand unifying theories. A cynic could even argue funding incentives in biology encourage complexity: big labs are funded if they address very complicated, and thus more expensive to research, phenomena. Whether or not that's true, chemical reconstruction of the genome is a process from first principles, marking a change in approach that brings biological research closer in spirit to more technical fields. Venter seems to believe that answering questions such as, "Can we reconstruct life from its components?" "What genes are necessary for life?" "What do you really need to run cellular machinery?" and "What is a minimal organism that could survive?" will uncover first principles in biology, potentially structuring understanding deductively.
Venter's use of combinatorial biological research is another potential sea-change in the way understanding is developed. This use of massive computing is analogous to that occurring in many other areas of scientific research, and the key is that discovery becomes less constrained by a priori assumptions or models (or understanding?).
Moore's Law and ever cheaper digital storage is giving scientists the luxury of solution search within increasingly large problem spaces. With complete search over the space of all possible solutions, in principle it is no longer necessary to reason one's way to the (an?) answer. This approach favors empirical evaluation over deductive reasoning. In Venter's biological context, presumably if automated search can find viable new species it will then be possible to investigate their unique life enabling characteristics. Perhaps through automated search?
JESSE DYLAN
Film-Maker, Form.tv, FreeForm.tv
What a revelation the The Master Class in Synthetic Genomics was. In addition to being informative on so many literal levels it reinforced the mystery and wonder of the world. George Church and Craig Venter were generous to give us a glimpse of where we are today and fire the imagination of where we are going. It's all science but seems beyond science fiction — living forever, reprogramming genes, resurrecting extinct species. All told at SpaceX — a place where people are reaching for the stars, not just thinking about it but building rockets to take us there. Where Elon Musk contemplates the vastness of space and our tiny place in it, where we gained a perspective on the things that are very small and beyond the vision of our eyes. So small it's a wonder we even know they are there. Thanks for giving us a profound glimpse into the future.
We are in such an early formative stage it makes one wonder where we will be in a hundred or even a thousand years. It's nice to be up against mysteries.
GEORGE DYSON
Science Historian; Darwin Among the Machines
End Of Species
We speak of reading and writing genomes — but no human mind can comprehend these lengthy texts. We are limited to snippet view in the library of life.
As Edge's own John Markoff reported from the recent Asilomar conference on artificial intelligence, the experts "generally discounted the possibility of highly centralized superintelligences and the idea that intelligence might spring spontaneously from the Internet."
Who will ever write the code that ignites the spark? Craig Venter might be hinting at the answer when he tells us that "DNA... is absolutely the software of life." The language used by DNA is much closer to machine language than any language used by human brains. It should be no surprise that the recent explosion of coded communication between our genomes and our computers largely leaves us out.
"The notion that no intelligence is involved in biological evolution may prove to be one of the most spectacular examples of the kind of misunderstandings which may arise before two alien forms of intelligence become aware of one another," wrote viral geneticist (and synthetic biologist) Nils Barricelli in 1963. The entire evolutionary process "is a powerful intelligence mechanism (or genetic brain) that, in many ways, can be comparable or superior to the human brain as far as the ability of solving problems is concerned," he added in 1987, in the final paper he published before he died. "Whether there are ways to communicate with genetic brains of different symbioorganisms, for example by using their own genetic language, is a question only the future can answer."
We are getting close.
ALEXANDRA ZUKERMAN
Assistant Editor, Edge
As the meaning of George Church and Craig Venter's words permeated my ever-forming pre-frontal cortex at the Master Class, I cannot deny that I felt similarly to the way George Eliot described her own emotions in 1879. Eliot, speaking as Theophrastus in a little-known collection of essays published that year, predicts that evermore perfecting machines will imminently supercede the human race in "Shadows of the Coming Race":
When, in the Bank of England, I see a wondrously delicate machine for testing sovereigns, a shrewd implacable little steel Rhadamanthus that, once the coins are delivered up to it, lifts and balances each in turn for the fraction of an instant, finds it wanting or sufficient, and dismisses it to right or left with rigorous justice; when I am told of micrometers and thermopiles and tasimeters which deal physically with the invisible, the impalpable, and the unimaginable; of cunning wires and wheels and pointing needles which will register your and my quickness so as to exclude flattering opinion; of a machine for drawing the right conclusion, which will doubtless by-and-by be improved into an automaton for finding true premises — my mind seeming too small for these things, I get a little out of it, like an unfortunate savage too suddenly brought face to face with civilisation, and I exclaim —
'Am I already in the shadow of the Coming Race? and will the creatures who are to transcend and finally supersede us be steely organisms, giving out the effluvia of the laboratory, and performing with infallible exactness more than everything that we have performed with a slovenly approximativeness and self-defeating inaccuracy?'1
Whereas Theophrastus' friend, Trost (a play on Trust) is confident that the human being is and will remain the "nervous center to the utmost development of mechanical processes" and that "the subtly refined powers of machines will react in producing more subtly refined thinking processes which will occupy the minds set free from grosser labour," Theophrastus feels "average" and less energetic, readily imagining his subjugation by these steely organisms giving out the "effluvia of the laboratory." He imagines instead that machines operate upon him, measuring his thoughts and quickness of mind. Micrometers, thermopiles and tasimeters were invading the sanctity of his consciousness with their "unconscious perfection." As George Church told us that "We're getting to a point where we can really program these cells as if they were an extension of a computer" and "This software builds its own hardware — it turns out biology does this really well," my sensibilities felt slightly jarred. Indeed, I felt as though I might be from an uncivilized time and place, suddenly finding myself on the platform as a flying train whizzed past (in fact, our tour of SpaceX and Tesla by Elon Musk was not far off!).
I asked myself the same question as George Eliot posed to herself over one hundred years ago: If computing and genetics are converging, such that computers will be reading our genomes and perfecting them, has not Eliot's prediction come true? I wondered, as a historian of science, not as much about the implications of such a development, but more about why computers have become so powerful. Why do we trust, as Trost does, artificial intelligence so much? Will scientists ultimately give their agency over to computers as we get closer to mediating our genomes and that of other forms of life? Will computers and artificial intelligence become a new "invisible hand" such as that which guides the free market without human intervention? I am curious about the role computers will be playing, as humans grant them more and more hegemony.
___1George Eliot, Impressions of Theophrastus Such
LAWRENCE KRAUSS
Physicist, Director, Origins Initiative, ASU; Author, Hiding In The Mirror
What struck me was the incredible power that is developing in bioinformatics and genomics, which so resembles the evolution in computer software and hardware over the past 30 years.
George Church's discussion of the acceleration of the Moore's law doubling time for genetic sequencing rates,, for example, was extraordinary, from 1.5 efoldings to close to 10 efoldings per year. When both George and Craig independently described their versions of the structure of the minimal genome appropriate for biological functioning and reproduction, I came away with the certainty that artificial lifeforms will be created within the next few years, and that they offered great hope for biologically induced solutions to physical problems, like potentially buildup of greenhouse gases.
At the same time, I came away feeling that the biological threats that come with this emerging knowledge and power are far greater than I had previously imagined, and this issue should be seriously addressed, to the extent it is possible. But ultimately I also came away with a more sober realization of the incredible complexity of the systems being manipulated, and how far we are from actually developing any sort of comprehensive understanding of the fundamental molecular basis of complex life. The simple animation demonstrated at the molecular level for Gene expression and replication demonstrated that the knowledge necessary to fully understand and reproduce biochemical activity in cells is daunting.
Two other comments: (1) was intrigued by the fact that the human genome has not been fully sequenced, in spite of the hype, and (2) was amazed at the available phase space for new discovery, especially in forms of microbial life on this planet, as demonstrated by Craig in his voyage around the world, skimming the surface, literally, of the ocean, and of course elsewhere in the universe, as alluded to by George.
Finally, I also began to think that structures on larger than molecular levels may be the key ones to understand for such things as memory, which make the possibilities for copying biological systems seem less like science fiction to me. George Church and I had an interesting discussion about this which piqued my interest, and I intend to follow this up.
![]()
FRANKFURTER ALLGEMEINE ZEITUNG
15. August 2009 FEUILLETON
GENETIC ENGINEERING
THE CURRENT CATALOG OF LIFE [Der Aktuelle Katalog Der Schöpfung Ist Da] By Ed Regis
[ED. NOTE: Among the attendees of the recent Edge Master Class 2009 — A Short Course on Synthetic Genomics, was science writer Ed Regis (What Is Life?) who was commissioned by Frank Schirrmacher, Co-Publisher and Feuilleton Editor of Frankfurter Allgemeine Zeitung to write a report covering the event. A German translation of Regis's article was published on August 15th by FAZ along with an accompanying article. The original English language version is published below with permission.]

In their futuristic workshops, the masters of the Synthetic Genomics, Craig Venter and George Church, play out their visions of bacteria reprogrammed to turn coal into methane gas and other microbes programmed to create jet fuel
14. August 2009 — John Brockman is a New York City literary agent with a twist: not only does he represent many of the world's top scientists and science writers, he's also founder and head of the Edge Foundation (www.edge.org), devoted to disseminating news of the latest advances in cutting-edge science and technology. Over the weekend of 24-26 July, in Los Angeles, Brockman's foundation sponsored a "master class" in which two of these same scientists — George Church, a molecular geneticist at Harvard Medical School, and Craig Venter, who helped sequence the human genome — gave a set of lectures on the subject of synthetic genomics. The event, which was by invitation only, was attended by about twenty members of America's technological elite, including Larry Page, co-founder of Google; Nathan Myhrvold, formerly chief technology officer at Microsoft; and Elon Musk, founder of PayPal and head of SpaceX, a private rocket manufacturing and space exploration firm which is housed in a massive hangar-like structure near Los Angeles International Airport. The first day's session, in fact, was held on the premises of SpaceX, where the Tesla electric car is also built.
Synthetic genomics, the subject of the conference, is the process of replacing all or part of an organism's natural DNA with synthetic DNA designed by humans. It is essentially genetic engineering on a mass scale. As the participants were to learn over the next two days, synthetic genomics will make possible a variety of miracles, such as bacteria reprogrammed to turn coal into methane gas and other microbes programmed to churn out jet fuel. Still other genomic engineering techniques will allow scientists to resurrect a range of extinct creatures including the woolly mammoth and, just maybe, even Neanderthal man.
The specter of "biohackers" creating new infectious agents made its obligatory appearance, but synthetic genomic researchers are, almost of necessity, optimists. George Church, one of whose special topics was "Engineering Humans 2.0," told the group that "DNA is excellent programmable matter." Just as automated sequencing machines can read the natural order of a DNA molecule, automated DNA synthesizing machines can create stretches of deliberately engineered DNA that can then be placed inside a cell so as to modify its normal behavior. Many bacterial cells, for example, are naturally attracted to cancerous tumors. And so by means of correctly altering their genomes it is possible to make a species of cancer-killing bacteria, organisms that attack the tumor by invading its cancerous cells, and then, while still inside them, synthesizing and then releasing cancer-killing toxins. ??Church and his Harvard lab team have already programmed bacteria to perform each of these functions separately, but they have not yet connected them all together into a complete and organized system. Still, "we're getting to the point where we can program these cells almost as if they were computers," he said.
But tumor-killing microbes were only a small portion of the myriad wonders described by Church. Another was the prospect of "humanized" or — even "personalized" — mice. These are mammals whose genomes are injected with bits of human DNA for the purpose of getting the animals to produce disease-fighting antibodies that would not be rejected by humans. A personalized mouse, whose genome was modified with some of your very own genetic material, would produce antibodies that would not be rejected by your own body.
Beyond that is the possibility of creating synthetic organisms that would be resistant to a whole class of natural viruses. There are two ways of doing this, one of which involves creating DNA that is a mirror-image of natural DNA. Like many biological and chemical substances, DNA has a chirality or handedness, the property of existing in either left-handed or right-handed structural forms. In their natural state, most biological molecules including DNA and viruses are left-handed. But by artificially constructing right-handed DNA, it would be possible to make synthetic living organisms whose DNA is a mirror-image of the original. They would be resistant to conventional enzymes, parasites, and predators because their DNA would not be recognized by the mirror-image version. Such synthetic organisms would constitute a whole new "mirror-world" of living things.
Church is also founder and head of the Personal Genome Project, or PGP. The project's purpose, he said, is to sequence the genomes of 100,000 volunteers with the goal of opening up a new era of personalized medicine. Instead of today's standardized, one-size-fits-all collection of pills and therapies, the medicine of the future will be genomically tailored to each individual patient, and its treatments will fit him or her as well as a made-to-order suit of clothes. Church also speculated that knowledge of the idiosyncratic features that lurk deep within each of our genomes — genetic differences that give rise to every person's respective set of individuating traits — will bring us an unprecedented level of self-understanding, and, therefore, will allow us to chart a more intelligent and informed course through life.
Toward the end of the first day Elon Musk, for whom the word charismatic could have well been coined, described a genomic transformation of another type. While a video of his Falcon 1 rocket being launched from the Kwajalein Atoll in the South Pacific played in the background, Musk spoke about sending the human species to the planets. That might have seemed an unrealistic goal were it not for the fact that on 13 July, just twelve days prior to the Edge event, SpaceX had successfully launched another Falcon 1 rocket that had placed Malaysia's RazakSAT into Earth orbit. Earlier, competing against both Boeing and Lockheed, SpaceX had won NASA's Commercial Orbital Transportation Services competition to resupply cargo to the International Space Station.
Then, like an emperor leading his subjects, Musk gave the conference attendees a tour of his spacecraft manufacturing facility. We saw the rocket engine assembly area, several launch vehicle components under construction, the mission operations area, and an example of the company's Dragon spacecraft, a pressurized capsule for the transport of cargo or passengers to the ISS.
"This is all geared to extending life beyond earth to a multiplanet civilization," Musk said of the spacecraft. Suddenly, his particular version of the future was no longer so unbelievable.
The leadoff speaker on the second and last day of the conference was J. Craig Venter, the human genome pioneer who more recently cofounded Synthetic Genomics Inc., an organization devoted to commercializing genomic engineering technologies. One of the challenges of synthetic genomics was to pare down organisms to the minimal set of genes needed to support life. Venter called this "reductionist biology," and said that a fundamental question was whether it would be possible to reconstruct life by putting together a collection of its smallest components.
Brewer's yeast, Venter discovered, could assemble fragments of DNA into functional chromosomes. He described a set of experiments in which he and colleagues created 25 small synthetic pieces of DNA, injected them into a yeast cell, which then proceeded to assemble the pieces into a chromosome. The trick was to design the DNA segments in such a way that the organism puts them together in the correct order. It was easy to manipulate genes in yeast, Venter found. He could insert genes, remove genes, and create a new species with new characteristics. In August 2007, he actually changed one species into another. He took a chromosome from one cell and put it into different one. "Changing the software [the DNA] completely eliminated the old organism and created a new one," Venter said.
Separately, Venter and his group had also created a synthetic DNA copy of the phiX virus, a small microbe that was not infectious to humans. When they put the synthetic DNA into an E. coli bacterium, the cell made the necessary proteins and assembled them into the actual virus, which in turn killed the cell that made it. All of this happened automatically in the cell, Venter said: "The software builds its own hardware."
These and other genomic creations, transformations, and destructions gave rise to questions about safety, the canonical nightmare being genomically engineered bacteria escaping from the lab and wreaking havoc upon human, animal, and plant. But a possible defense against this, Venter said, was to provide the organism with "suicide genes," meaning that you create within them a chemical dependency so that they cannot survive outside the lab. Equipped with such a dependency, synthetic organisms would pose no threat to natural organisms or to the biosphere. Outside the lab they would simply die.
That would be good news if it were true, because with funding provided by ExxonMobil, Venter and his team are now building a three to five square-mile algae farm in which reprogrammed algae will produce biofuels.
"Making algae make oil is not hard," Venter said. "It's the scalability that's the problem." Algae farms of the size required for organisms to become efficient and realistic sources of energy are expensive. Still, algae has the advantage that it uses CO2 as a carbon source — it actually consumes and metabolizes a greenhouse gas — and uses sunlight as an energy source. So what we have here, potentially, are living solar cells that eat carbon dioxide as they produce new hydrocarbons for fuel.
George Church had the final say in a lecture entitled "Engineering Humans 2.0." Human beings, he noted, are limited by a variety of things: by their ability to concentrate and remember, by the shortness of their lifespans, and so on. Genomic engineering could be used to correct all these deficiencies and more. The common laboratory mouse, he noted, had an average lifespan of 2.5 years. The naked mole rate, by contrast, lives ten times longer, to the ripe old age of 25. It would be possible to find the genes that contributed to the longevity of the naked mole rat, and by importing those genes into the lab mouse, you could slowly increase its longevity.
An analogous process could also be tried on human beings, increasing their lifespans and adding to their memory capacity, but the question was whether it was wise to do this. There were always trade-offs, Church said. You may engineer humans to have bigger and stronger bones, but only at the price if making them heavier and more ungainly. Malaria resistance is coupled with increased susceptibility to sickle cell anemia. And so on down the list. In a conference characterized by an excess of excess, Church provided a welcome cautionary note.
But then he proceeded to pull out all the stops an argued that by targeted genetic manipulation of the elephant genome it might be possible to resurrect the woolly mammoth. And by doing the same to the chimpanzee genome, scientists could possibly resurrect Neanderthal man.
"Why would anyone want to resurrect Neanderthal man?" a conference participant asked.
"To create a sibling species that would give us a fresh outlook on ourselves," Church answered. Humans were a monoculture, he said, and monocultures were biologically at risk.
His answer did not satisfy all of those present. "We already have enough Neanderthals in Washington," Craig Venter quipped, thereby effectively bringing the Edge Master Class 2009 to a close. ?
Ed Regis is the author of several science books, most recently, What Is Life? Investigating the Nature of Life in the Age of Synthetic Biology

SUEDDEUTSCHE ZEITUNG
August 13 , 2009
FEUILLETON
THE WALKMAN OF GENETIC ENGINEERING: THE MOVE FROM SCIENCE TO A NEW WORLD OF PRODUCTS
[Walkman der Gentechnik; Der Schritt von der Wissenschaft zu einer neuen Warenwelt] By Andrian Kreye, Editor, The Feuilleton, Sueddeutsche Zeitung
...Genetic engineering is now at a point where computer science was around the mid-eighties. The early PCs were limited as to purpose and network. In two and a half decades, the computer has led us into a digial world in which every aspect of lives has been affected. According to Moore's Law, the performance of computers doubles every 18 months. Genetic engineering is following a similar growth. On the last weekend in July, Craig Venter and George Church met in Los Angeles to lead a seminar on synthetic genetic engineering for John Brockman's science forum Edge.org.
Genetic engineering under Church has been following the grwoth of computer science growing by a factor of tenfold per year. After all, the cost of sequencing a genome dropped from three billion dollars in 2000 to around $50 000 dollars as Stanford University's Dr. Steven Quake genomics engineer announced this week. 17 commercial companies already offer similar services. In June, a "Consumer Genetics" exhibition was held in Boston for the first time. The Vice President of Knome, Ari Kiirikki, assumes that the cost of sequencing a genome in the next ten years will fall to less than $1,000. In support for this development, the X-Prize Foundation has put up a prize of ten million dollars for the sequencing of 100 full genomes within ten days for the cost of less than $10,000 dollars per genome sequenced. ??It is now up to the companies themselves to provide an ethical and legal standing to commercial genetic engineering. The States of New York and California have already made the sale of genetic tests subject to a prescription. This is however only a first step is to adjust a new a new commercialized science which is about to cause enormous changes similar to those brought about be computer science. Medical benefits are likely to be enormous. Who knows about dangers in its genetic make-up, can preventive measures meet. The potential for abuse is however likewise given. Health insurances and employers could discriminate against with the DNS information humans. Above all however our self-understanding will change. Which could change, if synthetic genetic engineering becomes a mass market, is not yet foreseeable. For example, Craig Venter is working on synthetic biofuels. If successful, such a development would re-align technology, economics and politics in a fundamental way. Of one thing we can already be certain. The question of whether genetic engineering will becomes available for all is no longer on the table. It has already happened.
SPIEGEL ONLINE
13.08. 2009
FEUILLETON-PRESSESCHAU
Süddeutsche Zeitung, 13.08.2009
Von aktuellen Entwicklungen aus der schönen neuen Welt der Genom-Sequenzierung berichtet Andrian Kreye: "Am letzten Juliwochenende trafen sich Craig Venter und George Church in Los Angeles, um für John Brockmans Wissenschaftsforum Edge.org ein Seminar über synthetische Gentechnik zu leiten. Die Gentechnik, so Church, habe die Informatik dabei längst hinter sich gelassen und entwickle sich mit einem Faktor von zehn pro Jahr. Immerhin - der Preis für die Sequenzierung eines Genoms ist von drei Milliarden Dollar im Jahr 2000 auf rund 50.000 Dollar gefallen, wie der Ingenieur der Stanford University Dr. Steven Quake diese Woche bekanntgab. 17 kommerzielle Firmen bieten ihre Dienste schon an."
Master Classes
Event Date: [ 7.25.08 ]
Location:
United States























The Gaige House
The Gaige House
Karla Taylor, Evan Williams
Karla Taylor, Evan Williams
The Gaige House
The Gaige House
Karla Taylor
Karla Taylor
Lunch
Lunch

[expand]
Daniel Kahneman & Richard Thaler
Edge Retreat, Spring Mountain Vineyard, Napa, California, August 22, 2013
What we're saying is that there is a technology emerging from behavioral economics. It's not only an abstract thing. You can do things with it. We are just at the beginning. I thought that the input of psychology into behavioral economics was done. But hearing Sendhil was very encouraging because there was a lot of new psychology there. That conversation is continuing and it looks to me as if that conversation is going to go forward. It's pretty intuitive, based on research, good theory, and important. — Daniel Kahneman
 |
 |
 |
| Richard Thaler | Sendhil Mullainathan | Daniel Kahneman |

Edge Master Class 2008
Richard Thaler, Sendhil Mullainathan, Daniel Kahneman
Sonoma, CA, July 25-27, 2008
A year ago, Edge convened its first "Master Class" in Napa, California, in which psychologist and Nobel Laureate Daniel Kahneman taught a nine-hour course: "A Short Course On Thinking About Thinking." The attendees were a "who's who" of the new global business culture.
The following year, in 2008, we invited Richard Thaler, the father of behavioral economics, to continue the conversation by organizing and leading the class: "A Short Course On Behavioral Economics."
Thaler arrived at Stanford in the 1970s to work with Kahneman and his late partner, Amos Tversky. Thaler, in turn, asked Harvard economist and former student Sendhil Mullainathan, as well as Kahneman, to teach the class with him.
The entire text to the 2008 Master Class is available online, along with video highlights of the talks and a photo gallery. The text also appears in a book privately published by Edge Foundation, Inc.
 |
 |
 |
| Nathan Myhrvold | Jeff Bezos | Elon Musk |
Whereas the focus for Kahneman's 2007 Master Class was on psychology, in 2008 the emphasis shifted to behavioral economics. As Kahneman noted: "There's new technology emerging from behavioral economics, and we are just starting to make use of that. I thought the input of psychology into economics was finished, but clearly it's not!"
The Master Classes are the most recent iteration in Edge's development, which began its activities under the name "The Reality Club" in 1981. Edge is different from The Algonquin, The Apostles, The Bloomsbury Group, or The Club, but it offers the same quality of intellectual adventure. The closest resemblances are to The Invisible College and the Lunar Society of Birmingham.
In contemporary terms, this results in Edge having a Google PageRank of "8," the same as The Atlantic, Corriere della Sera, The Economist, the Financial Times, Le Monde, The New Yorker, the New Statesman, Vanity Fair, the Wall Street Journal, the Washington Post, among others.
The early seventeenth-century Invisible College was a precursor to the Royal Society. Its members consisted of scientists such as Robert Boyle, John Wallis, and Robert Hooke. The Society's common theme was to acquire knowledge through experimental investigation. Another example is the nineteenth-century Lunar Society of Birmingham, an informal club of the leading cultural figures of the new industrial age—James Watt, Erasmus Darwin, Josiah Wedgwood, Joseph Priestley, and Benjamin Franklin.
In a similar fashion, Edge, through its Master Classes, gathers together intellectuals and technology pioneers. George Dyson, in his summary (below) of the second day of the proceedings, writes:
Retreating to the luxury of Sonoma to discuss economic theory in mid-2008 conveys images of Fiddling while Rome Burns. Do the architects of Microsoft, Amazon, Google, PayPal, and Facebook have anything to teach the behavioral economists—and anything to learn? So what? What's new?? As it turns out, all kinds of things are new. Entirely new economic structures and pathways have come into existence in the past few years.
Indeed, as one distinguished European visitor noted, the weekend, which involved the two-day Master Class in Sonoma followed by a San Francisco dinner, was "a remarkable gathering of outstanding minds. These are the people that are rewriting our global culture."
— John Brockman, Editor
 |
 |
 |
| Sean Parker | Salar Kamangar | Evan Williams |
RICHARD H. THALER is the Ralph and Dorothy Keller Distinguished Service Professor of Behavioral Science and Economics at Chicago's Booth School of Business and director of the University of Chicago’s Center for Decision Research. He is coauthor (with Cass Sunstein) of Nudge: Improving Decisions About Health, Wealth, and Happiness, and author of Misbehaving. Thaler is the recipient of the 2017 Nobel Prize in economics. Richard Thaler's Edge Bio Page


SENDHIL MULLAINATHAN, a professor of economics at Harvard, a recipient of a MacArthur Foundation "genius grant," conducts research on development economics, behavioral economics, and corporate finance. His work concerns creating a psychology of people to improve poverty alleviation programs in developing countries. He is executive director of Ideas 42, Institute of Quantitative Social Science, Harvard University. Sendhil Mullainathan's Edge Bio Page
DANIEL KAHNEMAN, a psychologist at Princeton University, is the recipient of the 2002 Nobel Prize in Economics for his pioneering work integrating insights from psychological research into economic science, especially concerning human judgment and decision-making under uncertainty. Daniel Kahneman's Edge Bio page
 |
 |
| George Dyson | Salar Kamangar, Evan Williams, Elon Musk, Katinka Matson |
PARTICIPANTS: Jeff Bezos, Founder, Amazon.com; John Brockman, Edge Foundation, Inc.; Max Brockman, Brockman, Inc.; George Dyson, Science Historian; Author, Darwin Among the Machines; W. Daniel Hillis, Computer Scientist; Cofounder, Applied Minds; Author, The Pattern on the Stone; Daniel Kahneman, Psychologist; Nobel Laureate, Princeton University; Salar Kamangar, Google; France LeClerc, Marketing Professor; Katinka Matson, Edge Foundation, Inc.; Sendhil Mullainathan, Professor of Economics, Harvard University; Executive Director, Ideas 42, Institute of Quantitative Social Science; Elon Musk, Physicist; Founder, Tesla Motors, SpaceX; Nathan Myhrvold, Physicist; Founder, Intellectual Venture, LLC; Event Photographer; Sean Parker, The Founders Fund; Cofounder: Napster, Plaxo, Facebook; Paul Romer, Economist, Stanford; Richard Thaler, Behavioral Economist, Director of the Center for Decision Research, University of Chicago Graduate School of Business; coauthor of Nudge; Anne Treisman, Psychologist, Princeton University; Evan Williams, Founder, Blogger, Twitter.
Further Reading on Edge:
"A Short Course In Thinking About Thinking"
Edge Master Class 2007
Daniel Kahneman
Auberge du Soleil, Rutherford, CA, July 20-22, 2007
A SHORT COURSE IN BEHAVIORAL ECONOMICS
CLASS ONE • CLASS TWO • CLASS THREE • CLASS FOUR • CLASS FIVE • CLASS SIX
PHOTO GALLERY
LIBERTARIAN PATERNALISM: WHY IT IS IMPOSSIBLE NOT TO NUDGE
(Class 1)
A Talk By Richard Thaler

Danny Hillis, Nathan Myhrvold, Daniel Kahneman, Jeff Bezos, Sendhil Mullainathan
If you remember one thing from this session, let it be this one: There is no way of avoiding meddling. People sometimes have the confused idea that we are pro meddling. That is a ridiculous notion. It's impossible not to meddle. Given that we can't avoid meddling, let's meddle in a good way. — Richard Thaler
IMPROVING CHOICES WITH MACHINE READABLE DISCLOSURE
(Class 2)
A Talk By Richard Thaler & Sendhil Mullainathan
Jeff Bezos, Nathan Myhrvold, Salar Kamangar, Daniel Kahneman, Danny Hillis, Paul Romer, Elon Musk, Sean Parker
At a minimum, what we're saying is that in every market where there is now required written disclosure, you have to give the same information electronically, and we think intelligently how best to do that. In a sentence that's the nature of the proposal.— Richard Thaler
THE PSYCHOLOGY OF SCARCITY
(Class 3)
A Talk By Sendhil Mullainathan

Nathan Myhrvold, Richard Thaler, Daniel Kahneman, France LeClerc, Danny Hillis, Paul Romer, George Dyson, Elon Musk, Jeff Bezos, Sean Parker
Let's put aside poverty alleviation for a second, and let's ask, "Is there something intrinsic to poverty that has value and that is worth studying in and of itself?" One of the reasons that is the case is that, purely aside from magic bullets, we need to understand if there unifying principles under conditions of scarcity that can help us understand behavior and to craft intervention. If we feel that conditions of scarcity evoke certain psychology, then that, not to mention pure scientific interest, will affect a vast majority of interventions. It's an important and old question.
TWO BIG THINGS HAPPENING IN PSYCHOLOGY TODAY
(Class 4)
A Talk By Daniel Kahneman

Danny Hillis, Richard Thaler, Nathan Myhrvold, Elon Musk, France LeClerc, Salar Kamangar, Anne Treisman, Sendhil Mullainathan, Jeff Bezos, Sean Parker
There's new technology emerging from behavioral economics and we are just starting to make use of that. I thought the input of psychology into economics was finished but clearly it's not!
THE REALITY CLUB
W. Daniel Hillis, Daniel Kahneman, Nathan Myhrvold, Richard Thaler on "Two Big Things Happening In Psychology Today"
THE IRONY OF POVERTY
(Class 5)
A Talk By Sendhil Mullainathan
Daniel Kahneman, Paul Romer, Richard Thaler, Danny Hillis, Jeff Bezos, Sean Parker, Anne Treisman, France LeClerc, Salar Kamangar, George Dyson
I want to close a loop, which I'm calling "The Irony of Poverty." On the one hand, lack of slack tells us the poor must make higher quality decisions because they don't have slack to help buffer them with things. But even though they have to supply higher quality decisions, they're in a worse position to supply them because they're depleted. That is the ultimate irony of poverty. You're getting cut twice. You are in an environment where the decisions have to be better, but you're in an environment that by the very nature of that makes it harder for you apply better decisions.
PUTTING PSYCHOLOGY INTO BEHAVIORAL ECONOMICS
(Class 6)
A Talk By Richard Thaler, Daniel Kahneman, Sendhil Mullainathan
Richard Thaler, Daniel Kahneman, Sendhil Mullainathan, Sean Parker, Anne Treisman, Paul Romer, Danny Hillis, Jeff Bezos, Salar Kamangar, George Dyson, France LeClerc
There's new technology emerging from behavioral economics and we are just starting to make use of that. I thought the input of psychology into economics was finished but clearly it's not!
PHOTO GALLERY
Edge Master Class & San Francisco Dinner

Photo Gallery: A Short Course In Behavioral Economics (Below)

Photo Gallery: The San Francisco 2008 Science Dinner
INTRODUCTION
By Daniel Kahneman
Many people think of economics as the discipline that deals with such things as housing prices, recessions, trade and unemployment. This view of economics is far too narrow. Economists and others who apply the ideas of economics deal with most aspects of life. There are economic approaches to sex and to crime, to political action and to mass entertainment, to law, health care and education, and to the acquisition and use of power. Economists bring to these topics a unique set of intellectual tools, a clear conception of the forces that drive human action, and a rigorous way of working out the social implications of individual choices. Economists are also the gatekeepers who control the flow of facts and ideas from the worlds of social science and technology to the world of policy. The findings of educators, epidemiologists and sociologists as well as the inventions of scientists and engineers are almost always filtered through an economic analysis before they are allowed to influence the decisions of policy makers.
In performing their function as gatekeepers, economists do not only apply the results of scientific investigation. They also bring to bear their beliefs about human nature. In the past, these beliefs could be summarized rather simply: people are self-interested and rational, and markets work. The beliefs of many economists have become much more nuanced in recent decades, and the approach that goes under the label of “behavioral economics” is based on a rather different view of both individuals and institutions. Behavioral economics is fortunate to have a witty guru—Richard Thaler of the University of Chicago Business School. (I stress this detail of his affiliation because the Economics Department of the University of Chicago is the temple of the “rational-agent model” that behavioral economists question.) Expanding on the idea of bounded rationality that the polymath Herbert Simon formulated long ago, Dick Thaler offered four tenets as the foundations of behavioral economics:
Bounded rationality
Bounded selfishness
Bounded self-control
Bounded arbitrage
The first three bounds are reasonably self-evident and obviously based on a plausible view of the psychology of the human agent. The fourth tenet is an observation about the limited ability of the market to exploit human folly and thereby to protect individual fools from their mistakes. The combination of ideas is applicable to the whole range of topics to which standard economic analysis has been applied—and at least some of us believe that the improved realism of the assumption yields better analysis and more useful policy recommendations.
Behavioral economics was influenced by psychology from its inception—or perhaps more accurately, behavioral economists made friends with psychologists, taught them some economics and learned some psychology from them. The little economics I know I learned from Dick Thaler when we worked together twenty-five years ago. It is somewhat embarrassing for a psychologist to admit that there is an asymmetry between the two disciplines: I cannot imagine a psychologist who could be counted as a good economist without formal training in that discipline, but it seems to be easier for economists to be good psychologists. This is certainly the case for both Dick and Sendhil Mullainathan—they know a great deal of what is going on in modern psychology, but more importantly they have superb psychological intuition and are willing to trust it.
Some of Dick Thaler’s most important ideas of recent years—especially his elaboration of the role of default options and status quo bias—have relied more on his flawless psychological sense than on actual psychological research. I was slightly worried by that development, fearing that behavioral economics might not need much input from psychology anymore. But the recent work of Sendhil Mullainathan has reassured me on this score as well as on many others. Sendhil belongs to a new generation. He was Dick Thaler’s favorite student as an undergraduate at Cornell, and his wonderful research on poverty is a collaboration with a psychologist, Eldar Shafir, who is roughly my son’s age. The psychology on which they draw is different from the ideas that influenced Dick. In the mind of behavioral economists, young and less young, the fusion of ideas from the two disciplines yields a rich and exciting picture of decision making, in which a basic premise—that the immediate context of decision making matters more than you think—is put to work in novel ways.
I happened to be involved in an encounter that had quite a bit to do with the birth of behavioral economics. More than twenty-five years ago, Eric Wanner was about to become the President of the Russell Sage Foundation—a post he has held with grace and distinction ever since. Amos Tversky and I met Eric at a conference on Cognitive Science in Rochester, where he invited us to have a beer and discuss his idea of bringing together psychology and economics. He asked how a foundation could help. We both remember my answer. I told him that this was not a project on which it was possible to spend a lot of money honestly. More importantly, I told him that it was futile to support psychologists who wanted to influence economics. The people who needed support were economists who were willing to be influenced. Indeed, the first grant that the Russell Sage Foundation made in that area allowed Dick Thaler to spend a year with me in Vancouver. This was 1983-1984, which was a very good year for behavioral economics. As the Edge Sonoma session amply demonstrated, we have come a long way since that day in a Rochester bar.
FIRST DAY SUMMARY—EDGE MASTER CLASS 2008
By Nathan Myhrvold
DR. NATHAN MYHRVOLD is CEO and managing director of Intellectual Ventures, a private entrepreneurial firm. Before Intellectual Ventures, Dr. Myhrvold spent fourteen years at Microsoft Corporation. In addition to working directly for Bill Gates, he founded Microsoft Research and served as Chief Technology Officer.
Nathan Myhrvold's Edge Bio Page
____________________________
The recent Edge event on behavioral economics was a great success. Here is a report on the first day.
Over the course of the last few years we've been treated to quite a few expositions of behavioral economics—probably a dozen popular books seek to explain some aspect of the field. This isn't the place for a full summary but the gist is pretty simple. Classical economics has studied a society of creatures that Richard Thaler, an economist at University of Chicago dubs the "Econ." Econs are rather superhuman in some ways—they do everything by optimizing utility functions, paragons of bounded rationality. Behavioral economics is about understanding how real live Humans differ from Econs.
In previous reading, and an Edge event last year I learned the most prominent differences between Econs and Humans. Humans, as it turns out, are not always bounded rational—they can be downright irrational. Thaler likes to say that Humans are like Homer Simpson. Econs are like Mr. Spock. This is a great start, but to have any substance in economics one has to understand that in the context of economic situations. Humans make a number of systematic deviations from the Econ ideal, and behavioral economics has categorized a few of these. So, for example, we humans fear loss more than we love gain. Humans care about how a question is put to them—propositions that an Econ would instantly recognize as mathematically equivalent seem different to Humans and they behave differently.
Daniel Kahneman, a Nobel laureate for his work in behavioral economics told us about priming—how a subtle influence radically shifts how people act. So, in one experiment people are asked to fill out a survey. In the corner of the room is a computer, with a screen saver running. That's it—nothing overt, just a background image in the room. If the screen saver shows pictures of money, the survey answers are radically different. Danny went through example after example like this where occurred. The first impulse one has in hearing this is no, this can't be the case. People can't be that easily and subconsciously influenced. You don't want to believe it. But Danny in his professorial way says, "Look, this is science. Belief isn't an option. Repeated randomized trials confirm the results. Get over it." The second impression is perhaps even more surprising—the influences are quite predictable. Show people images of money, and they tend to be more selfish and less willing to help others. Make people plot points on graph paper that are far apart, and they act more distant in lots of way. Make them plot points that are close together, and damned if they don't act closer. Again, it seems absurd, but cheap metaphors capture our minds. Humans, it seems, are like drunken poets, who can't glimpse a screen saver in the corner, or plot some points on graph paper without swooning under the metaphorical load and going off on tangents these stray images inspire.
This is all very strange, but is it important? The analogy that seems most apt to me is optical illusions. An earlier generation of psychologists got very excited about how the low level visual processing in our brains is hardwired to produce paradoxical results. The priming stories seem to me to be the symbolic and metaphorical equivalent. The priming metaphors in optical illusions are the context of the image—the extra lines or arrows that fool us into making errors in judgment of sizes or shapes. While one can learn to recognize optical illusions, you can't help but see the effect for what it is. Knowing the trick does not lessen its intuitive impact. You really cannot help but think one line is longer, even if you know that the trick will be revealed in a moment.
I wonder how closely this analogy carries over. Danny said today that you couldn't avoid priming. If he is right perhaps the analogy is close; but perhaps it's not.
I also can't help but wonder how important these effects are to thinking and decision making in general. After the early excitement about optical illusions, they have retreated from prominence—they explain a few cute things in vision, but they are only important in very artificial cases. Yes, there are a few cases where product design, architecture and other visual design problems are impacted by optical illusions, but very few. In most cases the visual context is not misleading. So, while it offers an interesting clue to how visual processing works, it is a rare special case that has little practical importance.
Perhaps the same thing is true here—the point of these psychological experiments, like the illusions, is to isolate an effect in a very artificial circumstance. This is a great way to get a clue about how the brain works (indeed it would seem akin to Steven Pinker's latest work The Stuff of Thought which argues for the importance of metaphors in the brain). But is it really important to day-to-day real world thinking? In particular, can economics be informed by these experiments? Does behavioral economics produce a systematically different result that classical economics if these ideas are factored in?
I can imagine it both ways. If it is important, then we are all at sea, tossed and turned in a tumultuous tide of metaphors imposed by our context. That is a very strange world—totally counter to our intuition. But maybe that is reality.
Or, I could equally imagine that it only matters in cases where you create a very artificial experiment—in effect, turning up the volume on the noise in the thought process. In more realistic contexts the signal trumps the noise.
The truth is likely some linear combination of these two extreme—but what combination? There are some great experiments yet to be done to nail that down.
Dick Thaler gave a fascinating talk that tries to apply these ideas in a very practical way. There is an old debate in economics about the right way to regulate society. Libertarians would say don't try—the harm in reducing choice is worse than the benefit, in part because of unintended consequences, but mostly because the market will reach the right equilibrium. Marxist economists, at the other extreme, took it for granted that one needs a dictatorship of the proletariat—choice is not an option, at least for the populace. Thaler has a new creation—a concept he calls "libertarian paternalism" which tries to split the baby.
The core idea (treated fully in his book Nudge) is pretty simple—present plenty of options, but then encourage certain outcomes by using behavioral economics concepts to stack the deck. A classic example is the difference between opt-in and opt-out in a program such as organ donation. If you tell people that they can opt-in to donating their organs if they are killed, a few will feel strongly enough to do it—most people won't. If you switch that to opt-out the reverse happens—very few people opt out. Changing the "choice architecture" that people have changes choices. This is not going to work on people who feel strongly, but the majority doesn't really care and can be pushed in one direction or another by choice architecture.
A better example is a program called "save more tomorrow" (SMT), for 401K plans in companies. People generally don't save very much. So, the "save more tomorrow" program lets you decide up front to save a greater portion of promotions and raises. You are not cutting into today's income (to which you feel you are entitled to spend) but rather you are pre-allocating a future windfall. Seems pretty simple but there are dramatic increases in savings rates when it is instituted.
Dick came to the session loaded for bear, expecting the objections of classical economics. Apparently this is all very controversial among economists and policy wonks. It struck me as very clever, but once explained, very obvious. Of course you can put some spin on the ball and nudge people the right way using to achieve a policy effect. It's called marketing when you do this in business, and it certainly can matter. In the world of policy wonk economists this may be controversial, but it wasn't to me.
An interesting connection with the discussion of priming experiments is that many policy contexts are highly artificial—very much like experiments. Filling out a driver's license form is a kind of questionnaire, and the organ donation scenario seems very remote to most people despite the fact that they're making a binding choice. The mechanics of opt-in versus opt-out or required choice could matter a lot in these contexts.
Dick has a bunch of other interesting ideas. One of them is to require that government disclosures on things like cell phone plans, or credit card statements be machine-readable disclosure with a standard schema. This would allow web sites to offer automated comparisons, and other tools to help people understand the complexities.
This is a fascinating idea that could have a lot of merit. Dick is, from my perspective, a bit over optimistic in some ways—it is unclear that it will be overwhelming. An example is unit prices in grocery stores—those little labels on store shelves that tell you that Progesso canned tomatoes are fifty-seven cents per pound, while the store brand is forty-three. Consumer advocates thought these would revolutionize consumer behavior—and perhaps they did in some limited ways. But premium brands didn't disappear.
I also differ on another point—must this be required by government, and would it be incorruptible were it so mandated. In the world of technology most standards are de facto, rather than de juris, and are driven by private owners (companies or private sector standards bodies), because the creation and maintenance of a standard is a dynamic balancing act—not static one. I think that many of the disclosure standards he seeks would be better done this way. Conversely, a government mandate disclosure standard might become so ossified by changing slowly that it did not achieve the right result. Nevertheless, this is a small point compared to the main idea, which is that machine-readable disclosures with standardized schema allow third party analysis and enables a degree of competition that would harder to achieve by other means.
Sendhil Mullainathan gave a fascinating talk about applying behavior economics to understand poverty. If this succeeds (it is a work in progress) it would be extremely important.
He showed a bunch of data on itinerant fruit vendors (all women) in India. Sixty-nine percent of them are constantly in debt to moneylenders who charge 5% per day interest. The fruit ladies make 10% per day profit, so half their income goes to the moneylender. They also typically buy a couple cups of tea per day. Sendhil shows that 1-cup of tea per day less would let them be debt free in thirty days, doubling their income. Thirty-one percent of these women have figured that out, so it is not impossible. Why don't the rest get there?
Sendhil then showed a bunch of other data arguing that poor people—even those in the US (who are vastly richer in absolute scale than his Indian fruit vendors)—do similar things with how they spend food stamps, or use of payday loans. He was very deliberate at drawing this out, until I finally couldn't stand it and blurted out "you're saying that they all have high discount rate". His argument is that under scarcity there is a systematic effect that you put the discount rate way too high for your own good. With too high a discount rate, you spend for the moment, not for the future. So, you have a cup a tea rather than double your income.
He is testing this with an amazing experiment. What would these women do if they could escape the "debt trap"? Bono, Jeffery Sachs and others have argued this point for poor nations—this is the individual version of the proposition.
Sendhil is studying 1000 of these fruit vendors (all women). Their total debt is typically $25 each, so he is just stepping in and paying off the debt for 500 of them! The question is then to see how many of them revert to being in debt over time, versus the 500 who are studied, but do not have their debt paid off. The experiment is underway and he has no idea what the result will be.
The interesting thing here is that, for these people, one can do a meaningful experiment (N = 500 gives good statistics) without much money in absolute. It would be hard to do this experiment with debt relief for poor nations, or even the US poor, but in India you can do serious field experiments for little money.
Sendhil also has an amusing argument, which is that very busy people are exactly like these poor fruit vendors. If you have very little time, it is scarce and you are as time-poor as the fruit ladies are cash-poor. So, you act like there is a high discount—and you commit to future events—like agreeing to travel and give a talk. Then as the time approaches, you tend to regret it and ask, "Why did I agree to this?" So you act like there is a high discount rate. This got everybody laughing. The difference here is that time can't be banked or borrowed, so it is unclear to me how close an analogy it is, but it was interesting nonetheless.
Indeed, I almost cancelled my attendance at this event right before hand, thinking, "why did I agree to this? I don't have the time!" After much wrestling I decided I could attend the first day, but no more. Well, this is one of those times when having the "wrong" discount rate is in your favor. I'm very glad I attended.
— Nathan Myhrvold
SECOND DAY SUMMARY—EDGE MASTER CLASS 2008
By George Dyson
GEORGE DYSON, a historian among futurists, is the author Baidarka; Project Orion; and Darwin Among the Machines.
____________________________
The weekend master class on behavioral economics was productive in unexpected ways, and a lot of good ideas and thoughts about implementing them were exchanged.
Day two (Sunday) opened with a session led by Sendhil Mullainathan, followed by a final wrap-up discussion before we adjourned at noon. Elon Musk, Evan Williams, and Nathan Myhrvold had departed early. In the absence of Nathan's high-resolution record, a brief summary, with editorial comments, is given here.
"I refuse to accept however, the stupidity of the Stock Exchange boys, as an explanation of the trend of stocks," wrote John von Neumann to Stanislaw Ulam, on December 9, 1939. "Those boys are stupid alright, but there must be an explanation of what happens, which makes no use of this fact." This question led von Neumann (with the help of Oskar Morgenstern) to his monumental Theory of Games and Economic Behavior, a precise mathematical structure demonstrating that a reliable economy can be constructed out of unreliable parts.
The von Neumann and Morgenstern approach (developed further by von Neumann's subsequent Probabilistic Logics and the Synthesis of Reliable Organisms From Unreliable Components) assumes that human unreliability and irrationality (by no means excluded from their model) will, in the aggregate, be filtered out. In the real world, however, irrational behavior (including the "stupidity of the stock exchange boys") is not completely filtered out. Daniel Kahneman, Richard Thaler, Sendhil Mullainathan, and their colleagues are developing an updated theory of games and economic behavior that does make use of this fact.
Sendhil Mullainathan opened the first hour, on the subject of scarcity, by repeating the first day's question: what is it that prevents the fruit vendors (who borrow their working capital daily at high interest) from saving their way out of recurring debt? According to Sendhil, many vendors do manage to escape, but a core-group remains trapped.
Sendhil shows a graph with $$ on the X-axis and Temptation on the Y-axis. The curve starts out flat and then ascends steeply upward before leveling off. The dangerous area is the steep slope when a person begins to acquire disposable income and meets rapidly increasing temptations. "To understand the behavior you have to understand the scale." Thaler interjects: "It's a mental accounting problem—but I think everything is a mental accounting problem." All human beings are subject to temptation, but the consequences are higher for the poor. Conclusion: temptation is a regressive tax.
Paul Romer notes that the temptation of time is a progressive tax, since time, unlike money, is evenly distributed, and wealthy people, no matter how well supplied with money, believe they have less spare time. Bottom line: the effects of temptation do not scale with income.
How best to intervene? Daniel Kahneman notes: "Some cultures have solved that problem... there seems to be a cultural solution." Sendhil, whose field research may soon have some answers, believes that lending at lower interest rates may help but will not solve the problem, and adds: "It would be better for the micro-financiers to come in and offer money at the same rate as the existing lenders, and then make the payoff in some other ways." The problem is the chronic effects of poverty, not the lending institutions (or lack thereof).
Sendhil moves the discussion to the subject of "depletion"—when judgment deteriorates due to the effects of stress. Clinical studies and real-world examples are described. Mental depletion correlates strongly with high serum cortisol (measurable in urine) and low glucose. Poverty produces chronic depletion, and decisions are impaired. High-value decisions are made under conditions of high stress. This results in what Sendhil terms the scarcity trap.
During the mid-morning break (with cookies), Richard Thaler shows videos from a forty-year-old study (Walter Mischel, 1973) of children offered one cookie now or two if they wait. The observed behavior correlates strongly, by almost any measure, with both the economic success of the parents and the child's future success. Hypothesis: small behavioral shifts might produce (or "nudge") large economic results.
After the break we begin to wrap things up. Richard Thaler suggests a "nudge" model of the world. The same way a digital camera has both an "expert mode" and an "idiot mode," what the economy needs is an "idiot mode" resistant to experts making mistakes.
Thaler notes that Government is really bad at building systems that can be operated in "idiot mode"—just compare private sector websites vs. public sector. Imagine if the Government had designed the user interface for Amazon!
Sendhil makes a final comment that elicits agreement all around: "R&D in the poverty space has huge potential returns and there is too little thinking about that."
Daniel Kahneman concludes: "There's new technology emerging from Behavioral Economics and we are just starting to make use of that. I thought the input of psychology into economics was finished but clearly it's not!" The meeting adjourns.
My personal conclusions: retreating to the luxury of Sonoma to discuss economic theory in mid-2008 conveys images of Fiddling while Rome Burns. Do the architects of Microsoft, Amazon, Google, PayPal, and Facebook have anything to teach the behavioral economists—and anything to learn? So what? What's new?? As it turns out, all kinds of things are new. Entirely new economic structures and pathways have come into existence in the past few years. More wealth is flowing ever more quickly, and can be monitored and influenced in real time. Models can be connected directly to the real world (for instance, Sendhil's field experiment, using real money to remove real debt, observing the results over time). The challenge is how to extend the current economic redistribution as efficiently (and beneficently) as possible to the less wealthy as well as the wealthy of the world.
A time of misguided economic decisions, while bad for many of us, is a good time for behavioral economics. As Abraham Flexner argued (26 September 1931) when urging the inclusion of a School of Economics at the founding of the Institute for Advanced Study: "The plague is upon us, and one cannot well study plagues after they have run their course." All the more so amidst the plagues of 2008.
It was Louis Bamberger's wish (23 April 1934), upon granting Abraham Flexner's request, that "the School of Economics and Politics may contribute not only to a knowledge of these subjects but ultimately to the cause of social justice which we have deeply at heart."
Master Classes
Event Date: [ 7.19.07 ]
Location:
United States























AUBERGE DU SOLEIL
AUBERGE DU SOLEIL
Session
Session
Table One
Table One
Table Two
Table Two
Table Three
Table Three
Pleasure & Pain
Pleasure & Pain
A SHORT COURSE IN THINKING ABOUT THINKING
Edge Master Class '07
DANIEL KAHNEMAN
Auberge du Soleil, Rutherford, CA, July 20-22, 2007
AN EDGE SPECIAL PROJECT


ATTENDEES: Jeff Bezos, Founder, Amazon.com; Stewart Brand, Cofounder, Long Now Foundation, Author, How Buildings Learn; Sergey Brin, Founder, Google; John Brockman, Edge Foundation, Inc.; Max Brockman, Brockman, Inc.; Peter Diamandis, Space Entrepreneur, Founder, X Prize Foundation; George Dyson, Science Historian; Author, Darwin Among the Machines; W. Daniel Hillis, Computer Scientist; Cofounder, Applied Minds; Author, The Pattern on the Stone; Daniel Kahneman, Psychologist; Nobel Laureate, Princeton University; Dean Kamen, Inventor, Deka Research; Salar Kamangar, Google; Seth Lloyd, Quantum Physicist, MIT, Author, Programming The Universe; Katinka Matson, Cofounder, Edge Foundation, Inc.; Nathan Myhrvold, Physicist; Founder, Intellectual Venture, LLC; Event Photographer; Tim O'Reilly, Founder, O'Reilly Media; Larry Page, Founder, Google; George Smoot, Physicist, Nobel Laureate, Berkeley, Coauthor, Wrinkles In Time; Anne Treisman, Psychologist, Princeton University;Jimmy Wales, Founder, Chair, Wikimedia Foundation (Wikipedia).
INTRODUCTION
By John Brockman
Recently, I spent several months working closely with Danny Kahneman, the psychologist who is the co-creator of behavioral economics (with his late collaborator Amos Tversky), for which he won the Nobel Prize in Economics in 2002.
My discussions with him inspired a 2-day "Master Class" given by Kahneman for a group of twenty leading American business/Internet/culture innovators—a microcosm of the recently dominant sector of American business—in Napa, California in July. They came to hear him lecture on his ideas and research in diverse fields such as human judgment, decision making and behavioral economics and well-being.
 Dean Kamen |
 Jeff Bezos |
 Larry Page |
While Kahneman has a wide following among people who study risk, decision-making, and other aspects of human judgment, he is not exactly a household name. Yet among many of the top thinkers in psychology, he ranks at the top of the field.
Harvard psychologist Daniel Gilbert (Stumbling on Happiness) writes: "Danny Kahneman is simply the most distinguished living psychologist in the world, bar none. Trying to say something smart about Danny's contributions to science is like trying to say something smart about water: It is everywhere, in everything, and a world without it would be a world unimaginably different than this one." And according to Harvard's Steven Pinker (The Stuff of Thought): "It's not an exaggeration to say that Kahneman is one of the most influential psychologists in history and certainly the most important psychologist alive today. He has made seminal contributions over a wide range of fields including social psychology, cognitive science, reasoning and thinking, and behavioral economics, a field he and his partner Amos Tversky invented."
 Jimmy Wales |
 Nathan Myhrvold |
 Stewart Brand |
Here are some examples from the national media which illustrate how Kahneman's ideas are reflected in the public conversation:
In the Economist "Happiness & Economics " issue in December, 2006, Kahneman is credited with the new hedonimetry regarding his argument that people are not as mysterious as less nosy economists supposed. "The view that hedonic states cannot be measured because they are private events is widely held but incorrect."
Paul Krugman, in his New York Times column, "Quagmire Of The Vanities" (January 8, 2007), asks if the proponents of the "surge" in Iraq are cynical or delusional. He presents Kahneman's view that "the administration's unwillingness to face reality in Iraq reflects a basic human aversion to cutting one's losses—the same instinct that makes gamblers stay at the table, hoping to break even."
His articles have been picked up by the press and written about extensively. The most recent example is Jim Holt's lede piece in The New York Times Magazine, "You are What You Expect" (January 21, 2007), an article about this year's Edge Annual Question "What Are You Optimistic About?". It was prefaced with a commentary regarding Kahneman's ideas on "optimism bias".
In Jerome Groopman's New Yorker article, "What's the trouble? How Doctors Think" (January 29, 2007), Groopman looks at a medical misdiagnosis through the prism of a heuristic called "availability," which refers to the tendency to judge the likelihood of an event by the ease with which relevant examples come to mind. This tendency was first described in 1973, in Kahneman's paper with Amos Tversky when they were psychologists at the Hebrew University of Jerusalem.
Kahneman's article (with Jonathan Renshon) "Why Hawks Win" was published in Foreign Policy (January/February 2007); Kahneman points out that the answer may lie deep in the human mind. People have dozens of decision-making biases, and almost all favor conflict rather than concession. The article takes a look at why the tough guys win more than they should. Publication came during the run up to Davis, and the article became a focus of numerous discussions and related articles.
The event was an unqualified success. As one of the attendees later wrote: "Even with the perspective a few weeks, I can still think it is one of the all time best conferences that I have ever attended."
 George Smoot |
 Daniel Kahneman |
 Sergey Brin |
Over a period of two days, Kahneman presided over six sessions lasting about eight hours. The entire event was videotaped as an archive. Edge is pleased to present a sampling from the event consisting of streaming video of the first 10-15 minutes of each session along with the related verbatim transcripts.
—JB
DANIEL KAHNEMAN is Eugene Higgins Professor of Psychology, Princeton University, and Professor of Public Affairs, Woodrow Wilson School of Public and International Affairs. He is winner of the 2002 Nobel Prize in Economic Sciences for his pioneering work integrating insights from psychological research into economic science, especially concerning human judgment and decision-making under uncertainty.
Daniel Kahneman's Edge Bio Page
Daniel Kahneman's Nobel Prize Lecture
SESSION ONE
I'll start with a topic that is called an inside-outside view of the planning fallacy. And it starts with a personal story, which is a true story....
KAHNEMAN: I'll start with a topic that is called an inside-outside view of the planning fallacy. And it starts with a personal story, which is a true story.

Well over 30 years ago I was in Israel, already working on judgment and decision making, and the idea came up to write a curriculum to teach judgment and decision making in high schools without mathematics. I put together a group of people that included some experienced teachers and some assistants, as well as the Dean of the School of Education at the time, who was a curriculum expert. We worked on writing the textbook as a group for about a year, and it was going pretty well—we had written a couple of chapters, we had given a couple of sample lessons. There was a great sense that we were making progress. We used to meet every Friday afternoon, and one day we had been talking about how to elicit information from groups and how to think about the future, and so I said, Let's see how we think about the future.
I asked everybody to write down on a slip of paper his or her estimate of the date on which we would hand the draft of the book over to the Ministry of Education. That by itself by the way was something that we had learned: you don't want to start by discussing something, you want to start by eliciting as many different opinions as possible, which you then you pool. So everybody did that, and we were really quite narrowly centered around two years; the range of estimates that people had—including myself and the Dean of the School of Education—was between 18 months and two and a half years.
But then something else occurred to me, and I asked the Dean of Education of the school whether he could think of other groups similar to our group that had been involved in developing a curriculum where no curriculum had existed before. At that period—I think it was the early 70s—there was a lot of activity in the biology curriculum, and in mathematics, and so he said, yes, he could think of quite a few. I asked him whether he knew specifically about these groups and he said there were quite a few of them about which he knew a lot. So I asked him to imagine them, thinking back to when they were at about the same state of progress we had reached, after which I asked the obvious question—how long did it take them to finish?
It's a story I've told many times, so I don't know whether I remember the story or the event, but I think he blushed, because what he said then was really kind of embarrassing, which was, You know I've never thought of it, but actually not all of them wrote a book. I asked how many, and he said roughly 40 percent of the groups he knew about never finished. By that time, there was a pall of gloom falling over the room, and I asked, of those who finished, how long did it take them? He thought for awhile and said, I cannot think of any group that finished in less than seven years and I can't think of any that went on for more than ten.
I asked one final question before doing something totally irrational, which was, in terms of resources, how good were we are at what we were doing, and where he would place us in the spectrum. His response I do remember, which was, below average, but not by much. [much laughter]
I'm deeply ashamed of the rest of the story, but there was something really instructive happening here, because there are two ways of looking at a problem; the inside view and the outside view. The inside view is looking at your problem and trying to estimate what will happen in your problem. The outside view involves making that an instance of something else—of a class. When you then look at the statistics of the class, it is a very different way of thinking about problems. And what's interesting is that it is a very unnatural way to think about problems, because you have to forget things that you know—and you know everything about what you're trying to do, your plan and so on—and to look at yourself as a point in the distribution is a very un-natural exercise; people actually hate doing this and resist it.
There are also many difficulties in determining the reference class. In this case, the reference class is pretty straightforward; it's other people developing curricula. But what's psychologically interesting about the incident is all of that information was in the head of the Dean of the School of Education, and still he said two years. There was no contact between something he knew and something he said. What psychologically to me was the truly insightful thing, was that he had all the information necessary to conclude that the prediction he was writing down was ridiculous.
COMMENT: Perhaps he was being tactful.
KAHNEMAN: No, he wasn't being tactful; he really didn't know. This is really something that I think happens a lot—the outside view comes up in something that I call ‘narrow framing,' which is, you focus on the problem at hand and don't see the class to which it belongs. That's part of the psychology of it. There is no question as to which is more accurate—clearly the outside view, by and large, is the better way to go.
Let me just add two elements to the story. One, which I'm really ashamed of, is that obviously we should have quit. None of us was willing to spend seven years writing the bloody book. It was out of the question. We didn't stop and I think that really was the end of rational planning. When I look back on the humor of our writing a book on rationality, and going on after we knew that what we were doing was not worth doing, is not something I'm proud of.
COMMENT: So you were one of the 40 percent in the end.
KAHNEMAN: No, actually I wasn't there. I got divorced, I got married, I left the country. The work went on. There was a book. It took eight years to write. It was completely worthless. There were some copies printed, they were never used. That's the end of that story. ...
SESSION TWO
Let me introduce a plan for this session. I'd like to take a detour, but where I would like to end up is with a realistic theory of risk taking. But I need to take a detour to make that sensible. I'd like to start by telling you what I think is the idea that got me the Nobel Prize—should have gotten Amos Tversky and me the Nobel Prize because it was something that we did together—and it's an embarrassingly simple idea. I'm going to tell you the personal story of this, and I call it "Bernoulli's Error"—the major theory of how people take risks...
KAHNEMAN: Let me introduce a plan for this session. I'd like to take a detour, but where I would like to end up is with a realistic theory of risk taking. But I need to take a detour to make that sensible. I'd like to start by telling you what I think is the idea that got me the Nobel Prize—should have gotten Amos Tversky and me the Nobel Prize because it was something that we did together—and it's an embarrassingly simple idea. I'm going to tell you the personal story of this, and I call it "Bernoulli's Error"—the major theory of how people take risks.
The quick history of the field is that in 1738 Daniel Bernoulli wrote a magnificent essay in which he presented many of the seminal ideas of how people take risks, published at the St. Petersburg Academy of Sciences. And he had a theory that explained why people take risks. Up to that time people were evaluating gambles by expected value, but expected value was never explained with conversion, and why people prefer to get sure things rather than gambles of equal expected value. And so he introduced the idea of utility (as a psychological variable), and that's what people assign to outcomes so they're not computing the weighted average of outcomes where the weights are the probabilities, they're computing the weighted average of the utilities of outcomes. Big discovery—big step in the understanding of it. It moves the understanding of risk taking from the outside world, where you're looking at values, to the inside world, where you're looking at the assignment of utilities. That was a great contribution.
He was trying to understand the decisions of merchants, really, and the example that he analyzes in some depth is the example of the merchant who has a ship loaded with spices, which he is going to send from Amsterdam to St. Petersburg – during the winter—with a 5 percent probability that the ship will be lost. That's the problem. He wants to figure out how the merchant is going to do this, when the merchant is going to decide that it's worth it, and how much insurance the merchant should be willing to pay. All of this he solves. And in the process, he goes through a very elaborate derivation of logarithms. He really explains the idea.
Bernoulli starts out from the psychological insight, which is very straightforward, that losing one ducat if you have ten ducats is like losing a hundred ducats if you have a thousand. The psychological response is proportional to your wealth. That very quickly forces a logarithmic utility function. The merchant assigns a psychological value to different states of wealth and says, if the ship makes it this is how wealthy I will be; if the ship sinks this is my wealth; this is my current wealth; these are the odds; you have a logarithmic utility function, and you figure it out. You know if it's positive, you do it; if it's not positive you don't; and the difference tells you how much you'd be willing to pay for insurance.
This is still the basic theory you learn when you study economics, and in business you basically learn variants on Bernoulli's utility theory. It's been modified, it's axiomatic and formalized, and it's no longer logarithmic necessarily, but that's the basic idea.
When Amos Tversky and I decided to work on this, I didn't know a thing about decision-making—it was his field of expertise. He had written a book with his teacher and a colleague called "Mathematical Psychology" and he gave me his copy of the book and told me to read the chapter that explained utility theory. It explained utility theory and the basic paradoxes of utility theory that have been formulated and the problems with the theory. Among the other things in that chapter were some really extraordinary people—Donald Davidson, one of the great philosophers of the twentieth century, Patrick Suppes—who had fallen love with the modern version of expected utility theory and had tried to measure the utility of money by actually running experiments where they asked people to choose between gambles. And that's what the chapter was about.
I read the chapter, but I was puzzled by something, that I didn't understand, and I assumed there was a simple answer. The gambles were formulated in terms of gains and losses, which is the way that you would normally formulate a gamble—actually there were no losses; there was always the choice between a sure thing and a probability of gaining something. But they plotted it as if you could infer the utility of wealth—the function that they drew was the utility of wealth, but the question they were asking was about gains.
I went back to Amos and I said, this is really weird: I don't see how you can get from gambles of gains and losses to the utility of wealth. You are not asking about wealth. As a psychologist you would know that if it demands complicated mathematical transformation, something is going wrong. If you want the utility of wealth you had better ask about wealth. If you're asking about gains, you are getting the utility of gains; you are not getting the utility of wealth. And that actually was the beginning of the theory that's called "Prospect Theory," which is considered a main contribution that we made. And the contribution is what I call "Bernoulli's Error". Bernoulli thought in terms of states of wealth, which maybe makes intuitive sense when you're thinking of the merchant. But that's not how you think when you're making everyday decisions. When those great philosophers went out to do their experiments measuring utility, they did the natural thing—you could gain that much, you could have that much for sure, or have a certain probability of gaining more. And wealth is not anywhere in the picture. Most of the time people think in terms of gains and losses.
There is no question that you can make people think in terms of wealth, but you have to frame it that way, you have to force them to think in terms of wealth. Normally they think in terms of gains and losses. Basically that's the essence of Prospect Theory. It's a theory that's defined on gains and losses. It adds a parameter to Bernoulli's theory so what I call Bernoulli's Error is that he is short one parameter.
I will tell you for example what this means. You have somebody who's facing a choice between having—I won't use large units, I'll use the units I use for my students—2 million, or an equal probability of having one or four. And those are states of wealth. In Bernoulli's account, that's sufficient. It's a well-defined problem. But notice that there is something that you don't know when you're doing this: you don't know how much the person has now.
So Bernoulli in effect assumes, having utilities for wealth, that your current wealth doesn't matter when you're facing that choice. You have a utility for wealth, and what you have doesn't matter. Basically the idea that you're figuring gains and losses means that what you have does matter. And in fact in this case it does.
When you stop to think about it, people are much more risk-averse when they are looking at it from below than when they're looking at it from above. When you ask who is more likely to take the two million for sure, the one who has one million or the one who has four, it is very clear that it's the one with one, and that the one with four might be much more likely to gamble. And that's what we find.
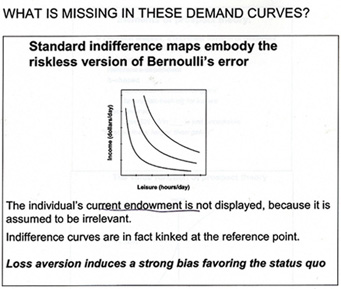
So Bernoulli's theory lacks a parameter. Here you have a standard function between leisure and income and I ask what's missing in this function. And what's missing is absolutely fundamental. What's missing is, where is the person now, on that tradeoff? In fact, when you draw real demand curves, they are kinked; they don't look anything like this. They are kinked where the person is. Where you are turns out to be a fundamentally important parameter.
Lots of very very good people went on with the missing parameter for three hundred years—theory has the blinding effect that you don't even see the problem, because you are so used to thinking in its terms. There is a way it's always done, and it takes somebody who is naïve, as I was, to see that there is something very odd, and it's because I didn't know this theory that I was in fact able to see that.
But demand curves are wrong. You always want to know where the person is. ...
SESSION THREE
The word "utility" that was mentioned this morning has a very interesting history – and has had two very different meanings. As it was used by Jeremy Bentham, it was pain and pleasure—the sovereign masters that govern what we do and what we should do – that was one concept of utility. In economics in the twentieth century, and that's closely related to the idea of the rational agent model, the meaning of utility changed completely to become what people want. Utility is inferred from watching what people choose, and it's used to explain what they choose. Some columnist called it "wantability". It's a very different concept...
The word "utility" that was mentioned this morning has a very interesting history – and has had two very different meanings. As it was used by Jeremy Bentham, it was pain and pleasure—the sovereign masters that govern what we do and what we should do – that was one concept of utility. In economics in the twentieth century, and that's closely related to the idea of the rational agent model, the meaning of utility changed completely to become what people want. Utility is inferred from watching what people choose, and it's used to explain what they choose. Some columnist called it "wantability". It's a very different concept.
One of the things I did some 15 years ago was draw a distinction, which obviously needed drawing. between them just to give them names. So "decision utility" is the weight that you assign to something when you're choosing it, and "experience utility", which is what Bentham wanted, is the experience. Once you start doing that, a lot of additional things happen, because it turns out that experience utility can be defined in at least two very different ways. One way is when a dentist asks you, does it hurt? That's one question that's got to do with your experience of right now. But what about when the dentist asks you, Did it hurt? and he's asking about a past session. Or it can be Did you have a good vacation? You have experience utility, which is everything that happens moment by moment by moment, and you have remembered utility, which is how you score the experience once it's over.
And some fifteen years ago or so, I started studying whether people remembered correctly what had happened to them. It turned out that they don't. And I also began to study whether people can predict how well they will enjoy what will happen to them in future. I used to call that "predictive utility", but Dan Gilbert has given it a much better name; he calls it "affective forecasting". This predicts what your emotional reactions will be. It turns out people don't do that very well, either.
Just to give you a sense of how little people know, my first experiment with predictive utility asked whether people knew how their taste for ice cream would change. We ran an experiment at Berkeley when we arrived, and advertised that you would get paid to eat ice cream. We were not short of volunteers. People at the first session were asked to list their favorite ice cream and were asked to come back. In the first experimental session they were given a regular helping of their favorite ice cream, while listening to a piece of music—Canadian rock music—that I had actually chosen. That took about ten-fifteen minutes, and then they were asked to rate their experience.
Afterward, they were also told, because they had undertaken to do so, that they would be coming to the lab every day at the same hour for I think eight working days, and every day they would have the same ice cream, the same music, and rate it. And they were asked to predict their rating tomorrow and their rating on the last day.
It turns out that people can't do this. Most people get tired of the ice cream, but some of them get kind of addicted to the ice cream, and people do not know in advance which category they will belong to. The correlation between what the change that actually happened in their tastes and the change that they predicted was absolutely zero.
It turns out—this I think is now generally accepted—that people are not good at affective forecasting. We have no problem predicting whether we'll enjoy the soup we're going to have now if it's a familiar soup, but we are not good if it's an unfamiliar experience, or a frequently repeated familiar experience. Another trivial case: we ran an experiment with plain yogurt, which students at Berkeley really didn't like at all, we had them eat yogurt for eight days, and after eight days they kind of liked it. But they really had no idea that that was going to happen. ...
SESSION FOUR
Fifteen years ago when I was doing those experiments on colonoscopies and the cold pressure stuff, I was convinced that the experience itself is the only one that matters, and that people just make a mistake when they choose to expose themselves to more pain. I thought it was kind of obvious that people are making a mistake—particularly because when you show people the choice, they regret it—they would rather have less pain than more pain. That led me to the topic of well-being, which is the topic that I've been focusing on for more than ten years now...
Fifteen years ago when I was doing those experiments on colonoscopies and the cold pressure stuff, I was convinced that the experience itself is the only one that matters, and that people just make a mistake when they choose to expose themselves to more pain. I thought it was kind of obvious that people are making a mistake—particularly because when you show people the choice, they regret it—they would rather have less pain than more pain. That led me to the topic of well-being, which is the topic that I've been focusing on for more than ten years now. And the reason I got interested in that was that in the research on well-being, you can again ask, whose well-being do we care for? The remembering self?—and I'll call that the remembering-evaluating self; the one that keeps score on the narrative of our life—or the experiencing self? It turns out that you can distinguish between these two. Not surprisingly, essentially all the literature on well-being is about the remembering self.
Millions of people have been asked the question, how satisfied are you with your life? That is a question to the remembering self, and there is a fair amount that we know about the happiness or the well-being of the remembering self. But the distinction between the remembering self and the experiencing self suggests immediately that there is another way to ask about well-being, and that's the happiness of the experiencing self.
It turns out that there are techniques for doing that. And the technique—it's not at all my idea—is experience sampling. You may be familiar with that—people have a cell phone or something that vibrates several times a day at unpredictable intervals. Then they get questions on the screen that say, what are you doing? and there is a menu—and Who are you with? and there is a menu—and How do you feel about it ?—and there is a menu of feelings.
This comes as close as you can to dispensing with the remembering self. There is an issue of memory, but the span of memory is really seconds, and people take a few seconds to do that; it's quite efficient, then you can collect a fair amount of data. So some of what I'm going to talk about is the two pictures that you get, which are not exactly the same, when you look at what makes people satisfied with their life and makes them have a good time.
But first I thought I'd show you the basic puzzles of well-being. There is a line on the "Easterlin Paradox" that goes almost straight up, which is GDP per capita. The line that isn't going anywhere is the percentage of people who say they are very happy. And that's a remembering self-type of question. It's one big puzzle of the well-being research, and it has gotten worse in the last two weeks because there are now new data on international comparisons that makes the puzzle even more surprising.
But this is within-country. And within the United States, it's the same for Japan, over a period where real income grew by a factor of four or more, you get nothing on life satisfaction. Which is sort of troubling for economists, because things are improving. I once had that conversation with an economist, David Card, at Berkeley—he used to be at Princeton—and asked him, how would an economist measure well-being? He looked at me as if I were asking a silly question and said, "income of course". I said, well what's the next measure? He said, "log income". [laughter] And the general idea is that the more money you have, the more choices you have—the more options you have—and that giving people more options can only make them better off . This is the fundamental idea of economic analysis. It turns out probably to be false, but it doesn't correspond to these data. So Easterlin as an economist caused some distress in the profession with these results.
So what is the puzzle here? The puzzle is related to the affective forecasting that most people believe that circumstances like becoming richer will make them happier. It turns out that people's beliefs about what will make them happier are mostly wrong, and they are wrong in a directional way, and they are wrong very predictably. And there is a story here that I think is interesting.
When people did studies of various categories of people, like the rich and the poor, you find differences in life satisfaction. But everybody looks at those differences is surprised by how small they are relative to the variability within each of these categories. You address the healthy and the unhealthy: very small differences.
Age—people don't like the idea of aging, but, at least in the United States, people do not become less happy or less satisfied with their life as they age. So a lot of the standard beliefs that people have about life satisfaction turn out to be false. This is a whole line of research—I was doing predictive utility, and Dan Gilbert invented the term "affective forecasting", which is a wonderful term, and did a lot of very insightful studies on that.
As an example of the kinds of studies he did, he asked people —I think he started that research in '92 when Bush became governor of Texas, running against Ann Richards—before the election, (Democrats and Republicans), how happy do you think you will be depending on whether Ann Richards or George Bush is elected. People thought that it would actually make a big difference. But two weeks after the election, you come back and you get their life satisfaction or their happiness and it's a blip, or nothing at all.
QUESTION: What about four years later?
KAHNEMAN: And interestingly enough, you know, there is an effect of political events on life satisfaction. But that effect, like the effect of other things like being a paraplegic or getting married, are all smaller than people expect.
COMMENT: Unless something goes really wrong.
KAHNEMAN: Unless something goes terribly wrong. ...
SESSION FIVE
I'll start with a couple of psychological notions.
There seems to be a very general psychological principle at work here, which is that sometimes when you are asked a question that is difficult, the mind doesn't stay silent if it doesn't have the answer. The mind produces something, and what it produces very characteristically is the answer to an easier but related question. That's one of the heuristics of good problem-solving, but it is a system one operation, which is an operation that takes place by itself.
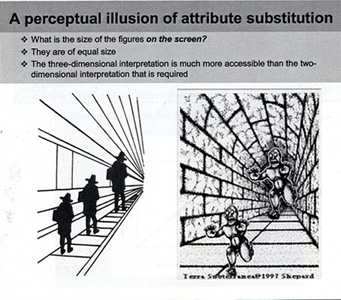
The visual illusions that you have here are that kind of thing because the question that people are asked is, what is the size of the three men on the page? When you look at it, you get a pretty compelling illusion (as it turns out to be) that the three men are not the same size on the page. They are different sizes. It is the same thing with the two monsters. When you take a ruler to them, they are of course absolutely identical. Now what seems to be happening here, is that we see the images three-dimensionally. If they were photographs of three-dimensional objects, of scenes, then indeed the person to the right would be taller than the person to the left. What's interesting about this is that people are not confused about the question that they've been asked; if you ask them how large the people are, they answer in fractions of an inch. They answer in centimeters, not meters. They know that they are supposed to give the two-dimensional size. they just cannot. What they do is give you something that is a scaling of a three-dimensional experience, and we call that "attribute substitution". That is, you try to judge an attribute and you end up judging something else. It turns out that this happens everywhere.
So the example I gave yesterday about happiness and dating is the same thing; you ask people how happy they are, and they tell you how happy they are with their romantic life, if that happens to be what's on the top of their mind at that moment. They are just substituting.
Here is another example. Some ten or fifteen years ago when there were terrorism scares in Europe but not in the States, people who were about to travel to Europe were asked questions like, How much would you pay for insurance that would return a hundred thousand dollars if during your trip you died for any reason. Alternatively other people were asked, how much would you pay for insurance that could pay a hundred thousand dollars if you died in a terrorist incident during your trip. People pay a lot more for the second policy than for the first. What is happening here is exactly what was happening with prolonging, the colonoscopy. And in fact psychologically– I won't have the time to go into the psychology unless you press me—but psychologically the same mechanism produces those violations of dominance, and basically what you're doing there is substituting fear.
You are asked how much insurance you would pay, and you don't know—it's a very hard thing to do. You do know how afraid you are, and you're more afraid of dying in a terrorist accident than you're afraid of dying. So you end up paying more because you map your fear into dollars and that's what you get.
Now if you ask people the two questions next to each other, you may get a different answer, because they see that one contains the other. A post-doc had a very nice idea. You ask people, How many murders are there every year in Michigan, and the median answer is about a hundred. You ask people how many murders are there every year in Detroit, and the median estimate is about two hundred. And again, you can see what is happening. The people who notice that, "oh, Michigan: Detroit is there" will not make that mistake. Or if asked the two questions next to each other, many people will understand and will do it right.
The point is that life serves us problems one at a time; we're not served with problems where the logic of the comparison is immediately evident so that we'll be spared the mistake. We're served with problems one at a time, and then as a result we answer in ways that do not correspond to logic.
In the case of time, we took the average instead of the integral. And we take the average instead of the integral in many other situations. Contingent valuation is a method where you survey people and ask them how much you should pay for different public goods. It's used in litigation, especially in environmental litigation; it's used in cost-benefit analysis—I think it's no good whatsoever, but this is an example to study.

How much would you pay to save birds from drowning in oil ponds? There is a whole scenario of how the poor birds mistake the oil ponds for real water ponds, and so how much should we pay to basically cover the oil ponds with netting to prevent that from happening. Surprisingly, people are willing to pay quite a bit once you describe the scenario well enough. But one thing is, it doesn't matter what the number of birds is. Two thousand birds, two hundred thousand, two million, they will pay exactly the same amount.
QUESTION: This is not price per bird?
KAHNEMAN: No, this is total. And so the reason is the same reason that you had with time, taking an average instead of an integral. You're not thinking of saving two hundred thousand birds. You are thinking of saving a bird. The emotion is associated with the idea of saving a bird from drowning. The quantity is completely separate. Basically you're representing the whole set by a prototype incident, and you evaluate the prototype incident. All the rest are like that.
When I was living in Canada, we asked people how much money they would be willing to pay to clean lakes from acid rain in the Halliburton region of Ontario, which is a small region of Ontario. We asked other people how much they would be willing to pay to clean lakes in all of Ontario.
People are willing to pay the same amount for the two quantities because they are paying to participate in the activity of cleaning a lake, or of cleaning lakes. How many lakes there are to clean is not their problem. This is a mechanism I think people should be familiar with. The idea that when you're asked a question, you don't answer that question, you answer another question that comes more readily to mind. That question is typically simpler; it's associated, it's not random; and then you map the answer to that other question onto whatever scale there is—it could be a scale of centimeters, or it could be a scale of pain, or it could be a scale of dollars, but you can recognize what is going on by looking at the variation in these variables. I could give you a lot of examples because one of the major tricks of the trade is understanding this attribute substitution business. How people answer questions.
COMMENT: So for example in the Save the Children—types of programs, they focus you on the individual.
KAHNEMAN: Absolutely. There is even research showing that when you show pictures of ten children, it is less effective than when you show the picture of a single child. When you describe their stories, the single instance is more emotional than the several instances and it translates into the size of contributions.
People are almost completely insensitive to amount in system one. Once you involve system two and systematic thinking, then they'll act differently. But emotionally we are geared to respond to images and to instances, and when we do that we get what I call "extension neglect." Duration neglect is an example of, you have a set of moments and you ignore how many moments there are. You have a set of birds and you ignore how many birds there are. ...
SESSION SIX
The question I'd like to raise is something that I'm deeply curious about, which is what should organizations do to improve the quality of their decision-making? And I'll tell you what it looks like, from my point of view.
I have never tried very hard, but I am in a way surprised by the ambivalence about it that you encounter in organizations. My sense is that by and large there isn't a huge wish to improve decision-making—there is a lot of talk about doing so, but it is a topic that is considered dangerous by the people in the organization and by the leadership of the organization. I'll give you a couple of examples. I taught a seminar to the top executives of a very large corporation that I cannot name and asked them, would you invest one percent of your annual profits into improving your decision-making? They looked at me as if I was crazy; it was too much.
I'll give you another example. There is an intelligence agency, and the CIA, and a lot of activity, and there are academics involved, and there is a CIA university. I was approached by someone there who said, will you come and help us out, we need help to improve our analysis. I said, I will come, but on one condition, and I know it will not be met. The condition is: if you can get a workshop where you get one of the ten top people in the organization to spend an entire day, I will come. If you can't, I won't. I never heard from them again.
What you can do is have them organize a conference where some really important people will come for three-quarters of an hour and give a talk about how important it is to improve the analysis. But when it comes to, are you willing to invest time in doing this, the seriousness just vanishes. That's been my experience, and I'm puzzled by it.
Since I'm in the right place to raise that question, with the right people to raise the question, I will. What do you think? Where did this come from; can it be fixed; can it be changed; should it be changed? What is your view, after we have talked about these things?

One of my slides concerned why decision analysis didn't catch on. And it's actually a talk I prepared because 30 years ago we all thought that decision analysis was going to conquer the world. It was clearly the best way of doing things—you took Bayesian logic and utility theory, a consistent thing, and—you had beliefs to be separated from values, and you would elicit the values of the organization, the beliefs of the organization, and pull them together. It looked obviously like the way to go, and basically it's a flop.Some organizations are still doing it, but it really isn't what it was intended to be 30 years ago. ...

