
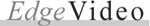
James Watson congratulates Craig Venter at conclusion of the lecture
WHAT IS LIFE? A 21st CENTURY PERSPECTIVE
J. CRAIG VENTER: I was asked earlier whether the goal is to dissect what Schrödinger had spoken and written, or to present the new summary, and I always like to be forward-looking, so I won't give you a history lesson except for very briefly. I will present our findings on first on reading the genetic code, and then learning to synthesize and write the genetic code, and as many of you know, we synthesized an entire genome, booted it up to create an entirely new synthetic cell where every protein in the cell was based on the synthetic DNA code.
As you all know, Schrödinger's book was published in 1944 and it was based on a series of three lectures here, starting in February of 1943. And he had to repeat the lectures, I read, on the following Monday because the room on the other side of campus was too small, and I understand people were turned away tonight, but we're grateful for Internet streaming, so I don't have to do this twice.
Also, due clearly to his historical role, and it's interesting to be sharing this event with Jim Watson, who I've known and had multiple interactions with over the last 25 years, including most recently sharing the Double Helix Prize for Human Genome Sequencing with him from Cold Spring Harbor Laboratory a few years ago.
Schrödinger started his lecture with a key question and an interesting insight on it. The question was "How can the events in space and time, which take place within the boundaries of a living organism be accounted for by physics and chemistry?" It's a pretty straightforward, simple question. Then he answered what he could at the time, "The obvious inability of present-day physics and chemistry to account for such events is no reason at all for doubting that they will be accounted for by those sciences." While I only have around 40 minutes, not three lectures, I hope to convince you that there has been substantial progress in the last nearly 70 years since Schrödinger initially asked that question, to the point where the answer is at least nearly at hand, if not in hand.
I view that we're now in what I'm calling "The Digital Age of Biology". My teams work on synthesizing genomes based on digital code in the computer, and four bottles of chemicals illustrates the ultimate link between the computer code and the digital code.
Life is code, as you heard in the introduction, was very clearly articulated by Schrodinger as code script. Perhaps even more importantly, and something I missed on the first few readings of his book earlier in my career, was as far as I could tell, it's the first mention that this code could be as simple as a binary code. And he used the example of how the Morse code with just dots and dashes, could be sufficient to give 34 different specifications. I've searched and I have not found any earlier references to the Morse code, although an historian that I know wrote Crick a letter asking about that, and Crick's response was, "It was a metaphor that was obvious to everybody." I don't know if it was obvious to everybody after Schrodinger's book, or some time before.
One of the things, though, Schrodinger was right about a lot of things, which is why, in fact, we celebrate what he talked about and what he wrote about, but some things he was clearly wrong about, like most scientists in his time, he relied on the biologist of the day. They thought that protein, not DNA was the genetic information. It's really quite extraordinary because just in 1944 in the same year that he published his book is when the famous experiment by Oswald Avery, who was 65 and about ready to retire, along with this colleagues, Colin MacLeod and Maclyn McCarty, published their key paper demonstrating that DNA was the substance that causes bacterial transformation, and therefore was the genetic material.
This experiment was remarkably simple, and I wonder why it wasn't done 50 years earlier with all the wonderful genetics work going on with drosophila, and chromosomes. Avery simply used proteolytic enzymes to destroy all the proteins associated with the DNA, and showed that the DNA, the naked DNA was, in fact, a transforming factor. The impact of this paper was far from instantaneous, as has happened in this field, in part because there was so much bias against DNA and for its proteins that it took a long time for them to sink in.
In 1949, was the first sequencing of a protein by Fred Sanger, and the protein was insulin. This work showed, in fact, that proteins consisted of linear amino acid codes. Sanger won the Nobel Prize in 1958 for his achievement. The sequence of insulin was very key in terms of leading to understanding the link between DNA and proteins. But as you heard in the introduction, obviously the discovery that changed the whole field and started us down the DNA route was the 1953 work by Watson and Crick with help from Maurice Wilkins and Rosalind Franklin showing that DNA was, in fact, a double helix which provided a clear explanation of how DNA could be self-replicated. Again, this was not, as I understand, instantly perceived as a breakthrough because of the bias of biochemists who were still hanging on to proteins as the genetic material. But soon with a few more experiments from others, the world began to change pretty dramatically.
The next big thing came from the work of Gobind Khorana and Marshall Nirenberg in 1961 where they worked out the triplet genetic code. It's three letters of genetic code, coding for each amino acid. With this breakthrough it became clear how the linear DNA code had coded for the linear protein code. This was followed a few years later by Robert Holley's discovery of the structure of tRNA, and tRNA is the key link between the messenger RNA and bringing in the amino acids in for protein synthesis. Holley, Nirenberg and Khorana shared the Nobel Prize in 1968 for their work.


The next decade brought us restriction enzymes from my friend and colleague, Ham Smith, who is at the Venter Institute now; in 1970 discovered the first restriction enzymes. These are the molecular scissors that cut DNA very precisely, and enabled the entire field of molecular engineering and molecular biology. Ham Smith, and Warner Arber, and Dan Nathans shared the Nobel prize in 1978 for their work. The '70s brought not only some interesting dress codes and characters, (Laughter) but the beginning of the molecular splicing revolution, using restriction enzymes, Cohen and Boyer, and Paul Berg all published the first papers on recombinant DNA, and Cohen and Boyer at Stanford filed a patent on their work, and this was used by Genentech and Eli Lilly to produce a human insulin as the first recombinant drug.
DNA sequencing and reading the genetic code progressed much more slowly. In 1973 Maxam and Gilbert published a paper on only 24 base pairs, 24 letters of genetic code. RNA sequencing progressed a little bit faster, so the first actual genome, a viral genome, an RNA viral genome was sequenced in 1976 by Walter Fiers from Belgium. This was followed by Fred Sanger's sequencing the first DNA virus, Phi X 174. This became the first viral DNA genome, and it was also accompanied by a new DNA sequencing technique of dideoxy DNA sequencing, now referred to as "Sanger sequencing" that Sanger introduced.
This is a picture of Sanger's team that sequenced Phi X 174. The second guy from the left on the bottom is Clyde Hutchison, who is also a member of the Venter Institute, and joined us after retiring from the University of North Carolina, and played a key role in some of the synthetic genome work.
In 1975 I was just getting my PhD as the first genes were being sequenced. Twenty years later I led the team to sequence the first genome of living species, and Ham Smith was part of that team. This was Haemophilus influenzae. Instead of 5,000 letters of genetic code, this was 1.8 million letters of genetic code. Or about 300 times the size of the Phi X genome. Five years later, we upped the ante another 1,600 times with the first draft of the human genome using our whole genome shotgun technique.
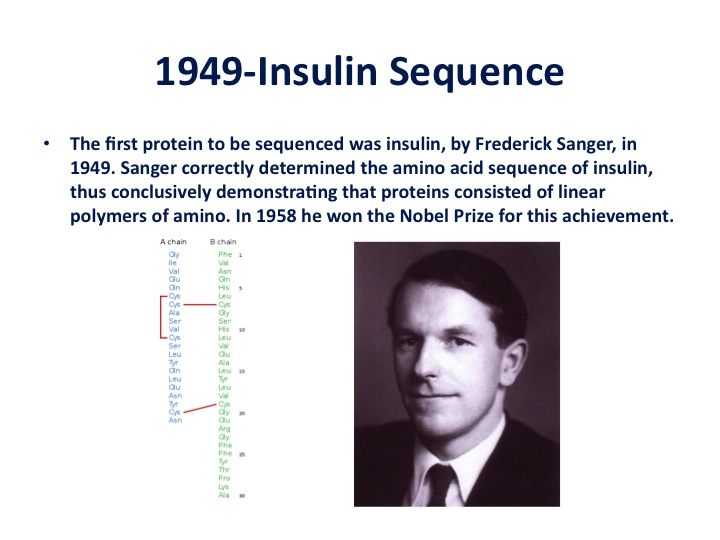
I view DNA as an analogue coding molecule, and when we sequence the DNA, we are converting that analogue code into digital code; the 1s and 0s in the computer are very similar to the dots and dashes of Schrodinger's metaphor. I call this process "digitizing biology".
The human genome is about a half a million times larger the Phi X genome, so it shows how fast things were developing. Reading genomes has now progressed extremely rapidly from requiring years or decades, it now takes about two hours to sequence a human genome. Instead of genomes per day or genomes per hour, or hours per genome, we can now and have recently done a demonstration sequencing 2,000 complete microbial genomes in one machine run. The pace is changing quite substantially.
I view DNA as an analogue coding molecule, and when we sequence the DNA, we are converting that analogue code into digital code; the 1s and 0s in the computer are very similar to the dots and dashes of Schrodinger's metaphor. I call this process "digitizing biology".
Numerous scientists have drawn the analogy between computers and biology. I take these even further. I describe DNA as the software of life and when we activate a synthetic genome in a recipient cell I describe it as booting up a genome, the same way we talk about booting up a software in a computer.
June 23rd of this year would have been Alan Turing's 100th birthday. Turing described what has become to be known as Turing Machines. The machine described a set of instructions written on a tape. He also described the Universal Turing Machine, which was a machine that could take that set of instructions and rewrite them, and this was the original version of the digital computer. His ideas were carried further in the 1940s by John von Neumann, and as many people know he conceived of the self-replicating machine. Von Neumann's machine consisted of a series of cells that uncovered a sequence of actions to be performed by the machine, and using the writing head, the machine can print out a new pattern of cells, allowing it to make a complete copy of itself on the tape. Many scientists have made the obvious analogy between Turing machines and biology. The latest was most recently in nature by Sydney Brenner who played a role in almost all the early stages of molecular biology. Brenner wrote an article about Turing and biology, and in this he argued that the best examples of Turing and von Neumann machines are from biology with the self-replicating code, the internal description of itself, and how this is the key kernel of biological theory.
While software was pouring out of sequencing machines around the world, substantial progress was going on describing the hardware of life, or proteins. In biochemistry the first two decades of the 20th century was dominated by what was called "The colloid theory". Life itself was explained in terms of the aggregate properties of all the colloidal substances in an organism. We now know that the substances are a collection of three-dimensional protein machines. Each evolved to carry out a very specific task.
Now, these proteins have been described as nature's robots. If you think about it for every single task in the cell, every imaginable task as described by Tanford and Reynolds, "there is a unique protein to carry out that task. It's programmed when to go on, when to go off. It does this based on its structure. It doesn't have consciousness; it doesn't have a control from the mind or higher center. Everything a protein does is built into its linear code, derived from the DNA code".
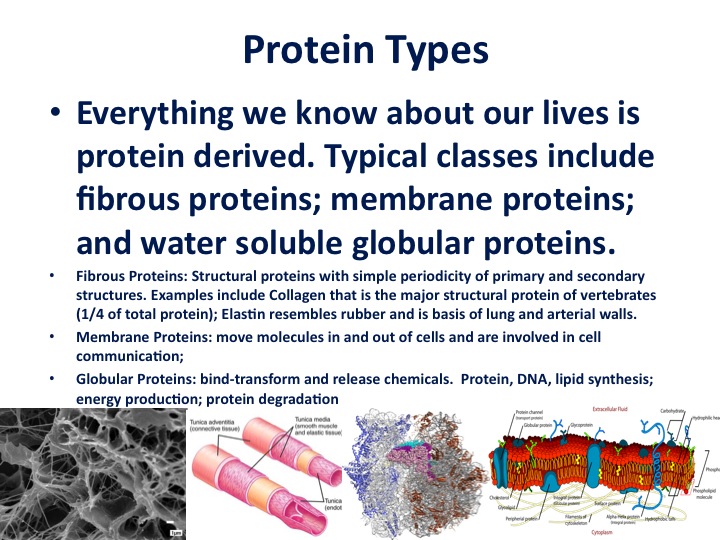
There are multiple protein types, everything you know about your own life, and most of it is protein-derived. About a quarter of your body is collagen, it's a matrix protein just built up of multiple layers. We have rubber-like proteins that form blood vessels as well as the lung tissue, and we have transporters that move things in and out of cells, and enzymes that copy DNA, metabolize sugars, et cetera.
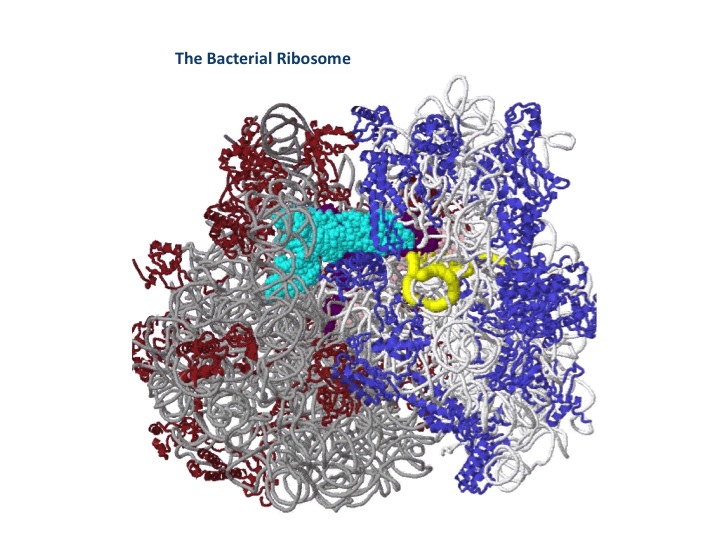
The most important breakthroughs, outside of the genetic code, was in determining the process of protein synthesis. To show you how recent all of this is, this is the three-dimensional structure of the bacterial ribosome determined in 2005, and the three-angstrom structure of the eukaryotic chromosome, which was just determined and published in December of last year. These ribosomes are extraordinary molecules. They are the most complex machinery we have in the cell, as you can see there are numerous components to it. I try to think of this as maybe the Ferrari engine of the cell. If the engine can't convert the messenger RNA tape into proteins, there is no life. If you interfere with that process, you kill life. It's the major antibiotics that we all know about, the amino glycosides, tetracycline, chloramphenicol, erythromycin, et cetera, all kill bacterial cells by interfering with the function of the ribosome.
The ribosome is clearly the most unique and special structure in the cell. It has seven major RNA chains, including three tRNA chains and one messenger RNA. It has 47 different proteins going into the structure and one newly synthesized protein chain, and a size of several million Daltons. This is the heart of all biology. We would not have cells, we would not have life without this machine that converts the linear DNA code into proteins working.
The process of converting the DNA code into protein starts with the synthesis of mRNA from DNA, called "transcription", and protein synthesis from the mRNA is called "translation". If these processes were highly reliable, life would be very different, and perhaps we would not need the same kind of information-driven system. If you were building a factory to build automobiles that worked the way the ribosome did, you would be out of business very quickly. A significant fraction of all the proteins synthesized, are degraded shortly after synthesis, because they formed the wrong confirmations and they aggregate in the cell, or cause some other problem.
Transfer RNA brings in the final amino acid to a growing peptide chain coming out of the ribosome. The next step is truly one of the most remarkable in nature, and that's the self-folding of the proteins. The number of potential protein confirmations is enormous: if you have 100 amino acids in a protein then there are on the order of 2 to the 100th power different conformations, and it would take about ten to the tenth years to try each conformation. But built into the linear protein code with each amino acid are the folding instructions in turn determined by the linear genetic code. As a result these processes happen very quickly.
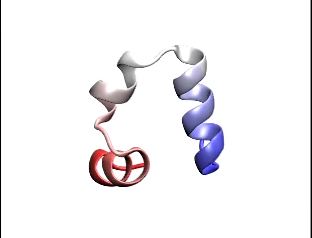
Here's a movie that spreads out 6 microseconds of protein folding over several seconds, to show you folding of a small protein. This is the end folded structure that starts with a linear protein, and over 6 microseconds it goes through all the different confirmations to try and get to the final fold.
Somehow the linear amino acid code limits the number of possible folds it can take, but each protein tries a large number of different ones, and if it gets them wrong in the end, the protein has to be degraded very quickly or it will cause problems. Imagine all the evolutionary selection that went into these processes, because the protein structure determines its rate of folding, as well as the final structure and hence its function. In fact, the end terminal amino acid determines how fast a protein is degraded. This is now called "The "N" rule pathway for protein degradation". For example, if you had the amino acid, lysine, or arginine or tryptophan as the N terminal on a protein beta-galactosidase, it results in a protein with a half-life of 120 seconds in E. coli, or 180 seconds in a eukaryotic cell, yeast. Whereas you have three different amino acids, serine, valine or methionine, you get a half-life of over ten hours of in bacteria, over 30 hours in yeast.
Because of the instability, aggregation and turnover of proteins in a cell one of the most important pathways in any cell is the proteolytic pathway. Degradation of proteins and protein fragments is of vital importance as they can be highly toxic to the cell by forming intracellular aggregates.
A bacterial cell in an hour or less will have to remake of all its proteins. Our cells make proteins at a similar rate, but because of protein instability and the random folding and misfolding of proteins, protein aggregation is a key problem. We have to constantly synthesize new proteins, and if they fold wrong, you have to get rid of them or they clog up the cell, the same way as if you stop taking out the trash in a city everything comes to a halt. Cells work the same way. You have to degrade the proteins; you have to pump the trash out of the cell. Miss folded proteins can become toxic very quickly. There are a number of diseases known to most of you that are due to misfolding or aggregation, Alzheimer's and mad cow disease are examples of diseases caused by the accumulation of toxic protein aggregates.
Life is a process of dynamic renewal. We're all shedding about 500 million skin cells every day. That is the dust that accumulates in your home; that's you. You shed your entire outer layer of skin every two to four weeks. You have five times ten to the 11th blood cells that die every day. If you're not constantly synthesizing new cells, you die.
Several human diseases arise from protein misfolding leaving too little of the normal protein to do its job properly. The most common hereditary disease of this type is cystic fibrosis. Recent research has clearly shown that the many, previously mysterious symptoms of this disorder all derive from lack of a protein that regulates the transport of the chloride ion across the cell membrane. More recently scientists have shown that by far the most common mutation underlying cystic fibrosis hinders the dissociation of the transport regulator protein from one of its chaperones. Thus, the final steps in normal folding cannot occur, and normal amounts of active protein are not produced.
I'm trying to leave you with a notion that life is a process of dynamic renewal. We're all shedding about 500 million skin cells every day. That is the dust that accumulates in your home; that's you. You shed your entire outer layer of skin every two to four weeks. You have five times ten to the 11th blood cells that die every day. If you're not constantly synthesizing new cells, you die. During normal organ development about half of all of our cells die. Everything in life is constantly turning over and being renewed by rereading the DNA software and making new proteins.
Life is a process of dynamic renewal. Without our DNA, without the software of life cells die very rapidly. Rapid protein turnover is not just an issue for bacterial cells; our 100 trillion human cells are constantly reading the genetic code and producing proteins. A recent study assaying 100 proteins in living human cancer cells showed half-lives that ranged between 45 minutes and 22.5 hours.
Now, as you know, all life is cellular, and the cellular theory of life is that you can only get life from preexisting cells, and all kinds of special vitalistic parameters have been attributed to cells over time. This slide shows what an artist's view of what a cell cytoplasm might look like. It's quite a crowded place, it's relatively viscous, it's not this empty bag with a few proteins floating around in it, and it's a very unique environment. About one quarter of the proteins are in solid phase.
A key tenant of chemistry is the notion of "synthesis as proof". This perhaps dates back to 1828 when Friedrich Wöhler synthesized urea. The Wöhler synthesis is of great historical significance because for the first time an organic compound was produced from inorganic reactants. Wöhler synthesis of urea was heralded as the end of vitalism because vitalists thought that you could only get organic molecules from living entities. Today there are tens of thousands of scientific papers published that either have "proof by synthesis" as the starting point or as a key part of the title.
We decided to take the approach of proof by synthesis that DNA codes for everything a cell produces and does. Back in 1995 when we sequenced the first genome, we sequenced a second genome that year. For comparative purposes we were looking for the cell with the smallest genome, and we chose mycoplasma genitalium. It has 482 protein-coding genes, and 43 RNA genes. We asked simple questions, how many of these genes are essential for life?; what's the smallest number of cells needed for a cellular machinery? After extensive experimentation we ultimately decided that the only way to answer these questions would be to design and construct a minimal DNA genome of the cell. As soon as we started down that route, we had new questions. Would chemistry even allow us to synthesize a bacterial chromosome? And if we could, would we just have a large piece of DNA, or could we boot it up in the cell like a new chemical piece of software?
We decided to start where DNA history started, with Phi X 174. We chose it as a test synthesis because you can make very few changes in the genetic code of Phi X without destroying viral particles. Clyde Hutchison, who helped sequence Phi X in Sanger's lab, Ham Smith and I developed a new series of techniques to correct the errors that take place when you synthesize DNA. The machines that synthesize DNA are not particularly accurate; the longer the piece of DNA you make, the more spelling errors. We had to find ways to correct errors.
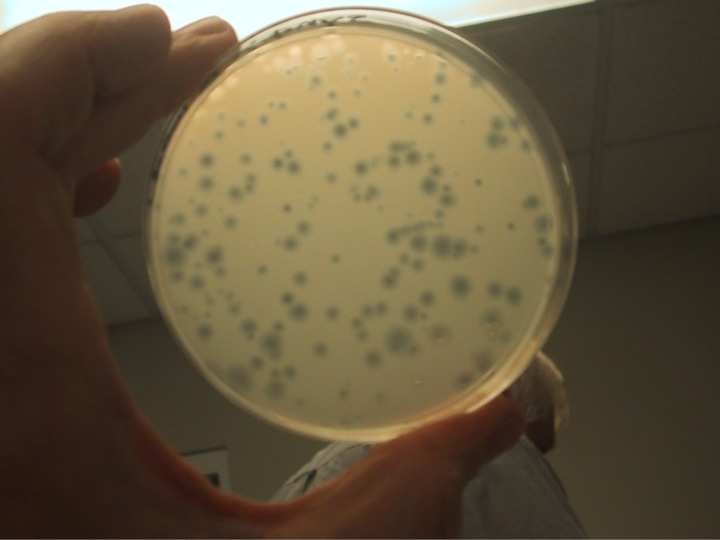
Starting with the digital code we synthesized DNA fragments and assembled the genome. We corrected the errors and in the end had a 5,386-basepair piece of DNA that we inserted into E. coli, and this is the actual photo of what happened. The E. coli recognized the synthetic piece of DNA as normal DNA, and the proteins, being robots, just started reading the synthetic genetic code, because that's what they're programmed to do. They made what the DNA code told them to do, to make the viral proteins. The virus proteins self-assembled and formed a functional virus. The virus showed its gratitude by killing the cells, which is how we effectively get these clear plaques in a lawn of bacterial cells. I call this a situation where the "software is building its own hardware". All we did was put a piece of DNA software in the cell, and we got out a protein virus with a DNA core.
Now, our goal is not to make viruses, we wanted to make something substantially larger. We wanted to make an entire chromosome of a living cell. But we thought if we could make viral-sized chromosomes accurately, maybe we could make 100 or so of those and find a way to put them together. That's what we did.
The teams starting with synthetic segments the size of Phi-X, we sequentially assembled larger and larger segments. At each stage we sequenced verified them before going on to the next assembly stage. We put four pieces together creating segments that were 24,000 letters long. We would clone the segments in E. coli, sequence them, and assemble three together, to get pieces that were 72,000 base pairs. This was a very laborious process that took about a year and a half to do.
We put two of the 72,000bp segments together to obtain new segments representing one quarter of the genome each at 144,000 letters in length. This was way beyond the largest piece that had ever been synthesized by other of only 30,000 base pairs. E. coli didn't like these large pieces of synthetic DNA in them, so we switched to yeast. I found out last night this is a city that loves beer that is produced from the same brewer's yeast. Aside from fermentation, this little cell has remarkable properties of assembling DNA.
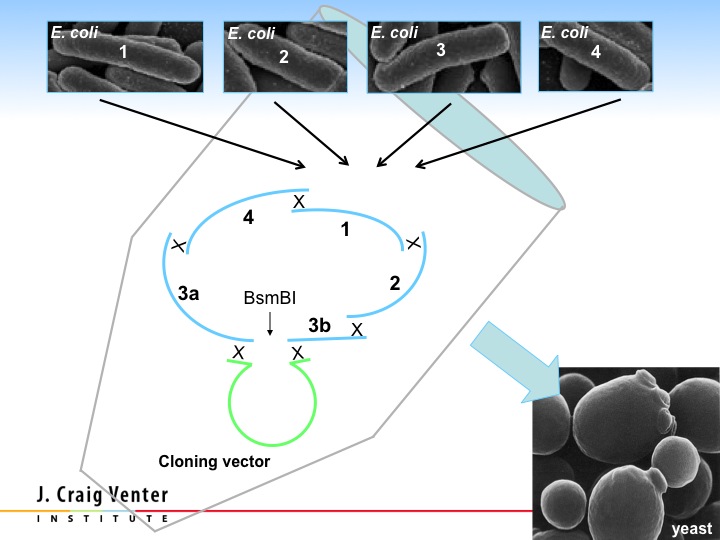
All we had to do was put the four synthetic quarter molecules into yeast with a small synthetic yeast centromere, and yeast automatically assembled these pieces together. That gave us the first synthetic bacterial chromosome, and this is what we published in 2008. This was the largest chemical of a defined structure ever synthesized.
We continued to work on DNA synthesis, and somebody who started out as a young post-doc, Dan Gibson, came up with a substantial breakthrough. Instead of the hours, to days, to years, he found out that by putting three enzymes together with all the DNA fragments in one tube at 50 degrees centigrade for a little while, they would automatically assemble these pieces. DNA assembly went from days down to an hour. This was a breakthrough for a number of reasons. Most importantly, it allows us now to automate genome synthesis. Having a simple one-step method allows us to go from the digital code in the computer to the analogue code of DNA in a robotic fashion. This means scaleing up substantially. We proved this initially by just one step synthesizing the mouse mitochondrial genome.
I had two teams working, one on the chemistry and one on the biology. It turns out the biology ended up being more difficult than the chemistry. How do you boot up a synthetic chromosome in a cell? This took substantial time to work out, and this paper that we published in 2007 is one of the most important for understanding how cells work and what the future of this field brings.
This paper is where we describe genome transplantation, and how by simply changing the genetic code, the chromosome, in one cell, swapping it out for another, we converted one species into another. Because this is so important to the theme of what we're doing, I'm going to walk you through this a little bit. And by the way, these are two of the scientists pictured here that led this effort, Carole Lartigue and John Glass, and the team working with them.


We started by isolating the chromosome from a cell called M. mycoides. Chromosomes are enshrouded with proteins, which is why there was confusion for so many years over whether the proteins or the DNA was the genetic material. We simply did what Avery did, we treated the DNA with proteolytic enzymes, removing all the proteins because if we're making a synthetic chromosome, we need to know can naked DNA work on its own, or are there going to be some special proteins needed for transplantation? We added a couple of gene cassettes to the chromosome, one so we could select for it, and another so it turns cells bright blue if it gets activated. After considerable effort we found a way to transplant this genome into a recipient cell, a cell M. capricolum, which is about the same distance apart genetically from M. mycoides as we are from mice. So relatively close, on the order of 10 percent or more different.
Life is based on DNA software. We're a DNA software system, you change the DNA software, and you change the species. It's a remarkably simple concept, remarkably complex in its execution.
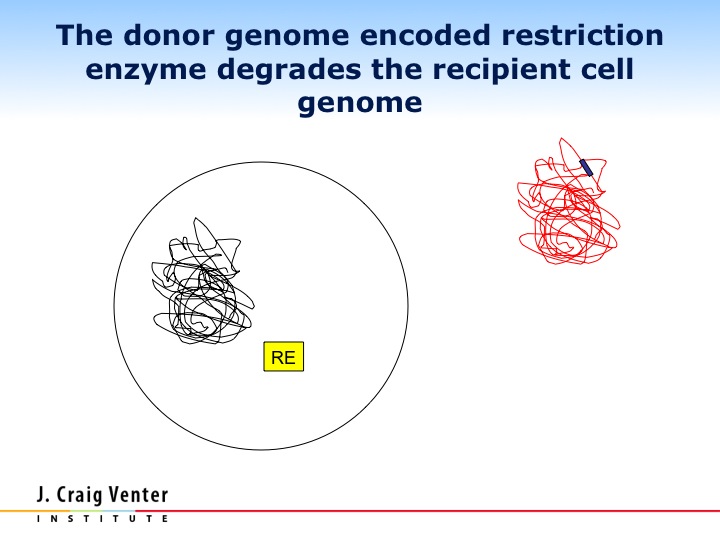
Let me show you what happened with this very sophisticated movie. We inserted the M. mycoides chromosome into the recipient cell. Just as with the Phi X, as soon as we put this DNA into this cell, the protein robots started producing mRNA, started producing proteins. Some of the early proteins produced were the restriction enzymes that Ham Smith discovered in 1970, we think that they recognized the initial chromosome in the cell as foreign DNA and chewed it up. Now we have the body and all the proteins of one species, and the genetic software of another. What happened?
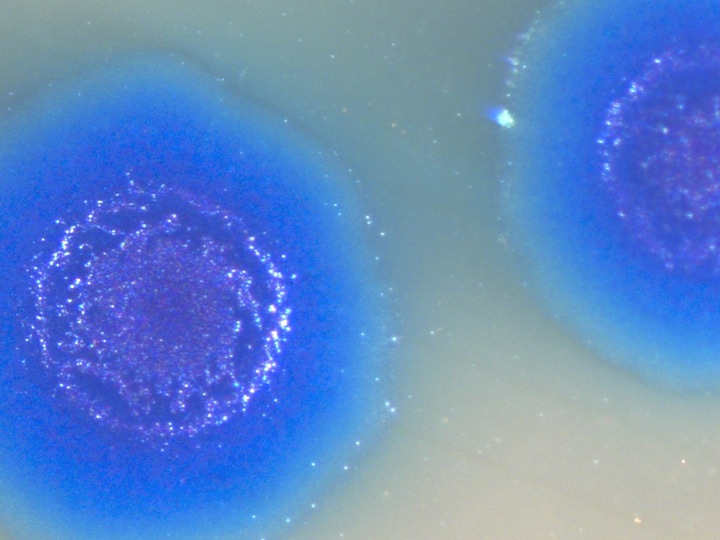
In a very short period of time we have these bright blue cells. When we interrogated the cells, they had only the transplanted genome, but more importantly, when we sequenced the proteins in these cells, there wasn't a single protein or other molecule from the original species. Every protein in the cell came from the new DNA that we inserted into the cell. Life is based on DNA software. We're a DNA software system, you change the DNA software, and you change the species. It's a remarkably simple concept, remarkably complex in its execution.
Now, we had a problem, that some of you may have picked up on or have read about. We were assembling the bacterial chromosome in a eukaryotic cell. If we're going to take the synthetic genome and do the transplantations, we had to find a way to get the genome out of yeast to transplant it back into the bacterial cell. We developed a whole new way to grow bacteria chromosomes in yeast as eukaryotic chromosomes. It was remarkably simple in the end. All we do is add a very small synthetic centromere from yeast to the bacterial chromosome, and all of a sudden it turns into a stable eukaryotic chromosome.
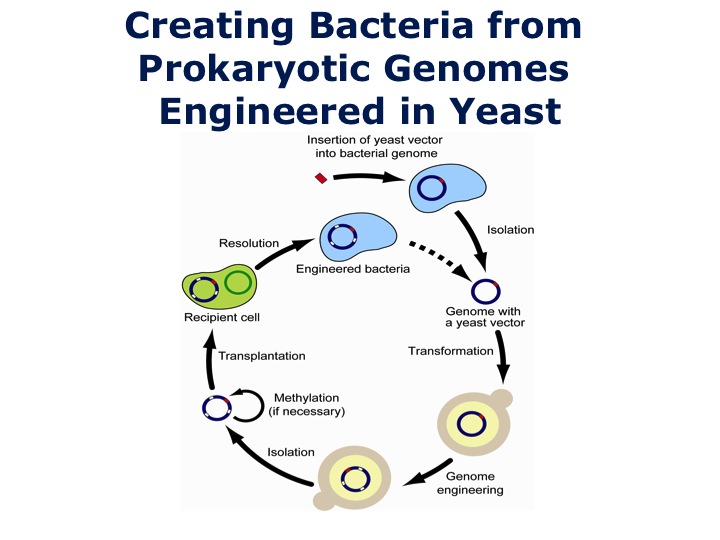

Now we can stabley grow bacterial chromosomes in yeast. We had the situation where we had the M. mycoides chromosome in the eukaryotic cell, we could try isolating it and doing a transplantation. The trouble is, it didn't work. This little problem took us two and a half years to solve of why it didn't work. It turns out when we initially did the transplantations taking the chromosome out of the M. mycoides cell, that DNA had been methylated, and that's how cells protect their own DNA from interloping species. We proved this by isolating the six methylases, and methylating the DNA when we took it out of yeast. If we methylated the DNA, we could then do the transplantation. We proved this ultimately by in the recipient cell removing the restriction enzyme system, and in that case we can just transplant the naked unmethylated DNA because there's nothing to destroy the DNA in the cell.
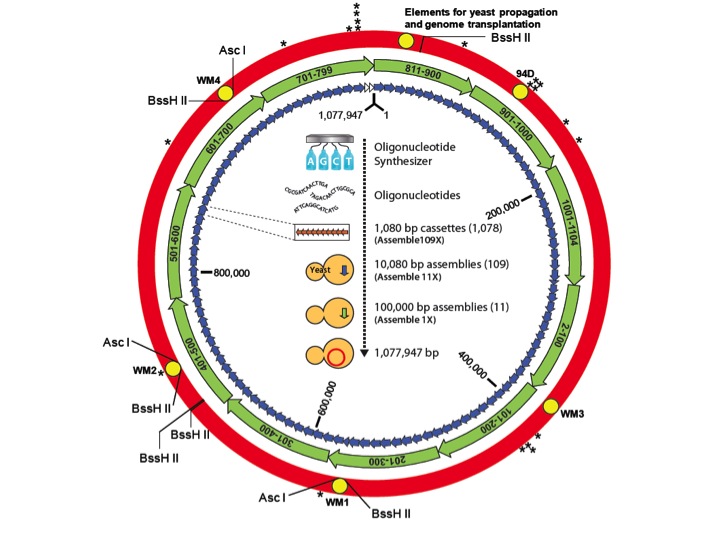
We were now at the point where we thought we had solved all the problems. We could create the new bacterial strains from the bacterial genomes cloned in yeast. We had this new cycle, we could work our way around the circle, we could add a centromere to the bacterial chromosome and turn it into a eukaryotic chromosome. The advantages, for those of you who work with bacteria, most bacteria do not have genetic systems, which is why most scientists don't work with them. As soon as you put that bacterial genome in yeast, we have the complete repertoire of genetic tools available in yeast such as homologous recombination. We can make rapid changes in the genome, isolate the chromosome, methylate it if necessary, and do a transplantation to create a highly modified cell.
With all the new techniques and success we decided to synthesize the much larger M. mycoides genome. Dan Gibson led the effort that started with pieces that were 1,000 letters long. We put ten of those together to make these over 10,000 letters long. We put ten of those together to make pieces now that are 100,000 letters long, and we had eleven 100,000 base pair pieces. We put them in yeast, which assembled the genome. We knew how to transplant it out of yeast and we did the transplantation and it didn't work.
Those of you who are software engineers know that software engineers have debugging software to tell them where the problems are in their code. So we had to develop the biological version of debugging software, which was basically substituting natural pieces of DNA for the synthetic ones so we could find out what was wrong. We found out we could have 10 of the 11 synthetic pieces, and the last piece had to be the native genome DNA to get a living cell. We re-sequenced our synthetic segment and found one letter wrong in an essential gene that made the difference between life and no life. The deletion was in the DNAa gene, which is an essential gene for life. We corrected that error, the one error out of 1.1 million, and we got the first actual synthetic cell from the genome transplants.

One of the ways that we knew that what we had was a synthetic cell was by watermarking the DNA so we could always tell our synthetic species from any naturally occurring one. Now about the watermarks, when we watermarked the first genome we just used the single letter amino acid code to write the authors names in the DNA. We were accused of not having much of an imagination. For this new genome we went a little bit farther by adding three quotations from the literature. But first the team developed a whole new code where by we could write the English language complete with numbers and punctuation in DNA code. It was quite interesting. We sent the paper to Science for a review, and one of the reviewers sent back their review written in DNA code, much to the frustration of the Science editor, who could not decipher it. (Laughter) But the reviewer's DNA code was based on the ASCII code, and with biology that creates a problem because you can get long stretches of new without a stop codon. We developed this new code that puts in very frequent stop codons, because the last thing you want to do is put in a quote from James Joyce and have it turn into a new toxin that kills the cell or kills you. You didn't know poetry could do that, I guess.
We built in the names of the 46 scientists that contributed to the effort, and also there was a message with an URL. So being the first species to have the computer as a parent, we thought it was appropriate it should have its own Web addressed built into the genome. As people solved this code, they would send an e-mail to the Web address written in the genome. Once numerous people solved it, we made this available.
The three quotes are the first one, and the probably most important one to this country is James Joyce, "To live, to err, to fall, to triumph, to recreate life out of life." Somehow that seemed highly appropriate. The second is from Oppenheimer's biography, "American Prometheus". "See things not as they are, but as they might be." In the third, from Richard Feynman, "What I cannot build, I cannot understand."
Everybody thought this was very cool until a few months after this appeared, we got a letter from James Joyce's estate attorney saying, "Did you seek permission to use this quotation?" In the US, at least, there are fair use laws that allow you to quote up to a paragraph without seeking permission. We sort of dismissed that one, and James Joyce was dead, and we didn't know how to ask him anyway.
Then we started getting an e-mail trail from a Caltech scientist saying we misquoted Richard Feynman. But if you look on the Internet, this is the quotation that you find everywhere. We argued back this is what we found, and this is what was in his biography. So to prove his point, he sent a picture of Feynman's blackboard with the original quotation, and it was, "What I cannot create, I do not understand." I think it's a much better quotation, and we've gone back to correct the DNA code so that Feynman can rest much more peacefully.

All living cells that we know of on this planet are DNA software driven biological machines comprised of hundreds to thousands of protein robots coded for by the DNA software. The protein robots carry out precise biochemical functions developed by billions of years of evolutionary software changes.
Science can go much further now, and there is an exciting paper out of Stanford with a team led by Markus Covert and that included John Glass from my institute using the work on the mycoplasma cell to do the first complete mathematical modeling of a cell. But this is coming out in Cell next week. It's going to be an exciting paper. We can go from the digital code to the genetic code, and now modeling the entire function of the cell in a computer, going the complete digital circle. We are going even further now, by using computer software to design new DNA software to create a new synthetic life.
I hope it is becoming clear that all living cells that we know of on this planet are DNA software driven biological machines comprised of hundreds to thousands of protein robots coded for by the DNA software. The protein robots carry out precise biochemical functions developed by billions of years of evolutionary software changes. The software codes for the linear protein sequence, which in turn determines the rate of folding as well as the final 3-dimensional structure and function of the protein robot. The primary sequence determines the stability of the protein and therefore its dynamic regulation in the cell. By making a copy of the DNA software, cells have the ability to self-replicate. All these processes require energy. From all the genomes we have sequenced we have seen that there is a range of mechanisms for the generation of cellular energy molecules through a process we call metabolism. Some cells are able to transport sugars across the membrane into the cell and by some now well defined enzymatic processes capture the chemical energy in the sugar molecule and to supply it to the required cellular processes. Other cells such as the autotroph Methanococcus jannaschii use only inorganic chemicals to make every molecule in the cell while providing the cellular energy. These cells do this by a series of proteins that convert carbon dioxide into methane to generate cellular energy molecules and to provide the carbon to make proteins. These processes are all coded for in the genetic code.
Schrödinger citing the second law of thermodynamics (entropy principal)-the natural tendency of things to go over into disorder, described his notion of "order based on order". We have now shown using synthetic DNA genomes that when you put new DNA software into the cell the protein robots coded for are produced, changing the cellular phenotype. When you change the DNA software you change the species. This is consistent with Schrodinger's Code-script and "An organism's astonishing gift of concentrating a 'stream of order' on itself …"
We can digitize life, and we generate life from the digital world. Just as the ribosome can convert the analogue message in mRNA into a protein robot, it's becoming standard now in the world of science to convert digital code into protein viruses and cells. Scientists send digital code to each other instead of sending genes or proteins. There are several companies around the world that make their living by synthesizing genes for scientific labs. It's faster and cheaper to synthesize a gene than it is to clone it, or even get it by Federal Express.
As an example BARDA in the US government sends us as a part of our synthetic genomic flu virus program with Novartis, an email with a test pandemic flu virus sequence. We convert the digital sequence into a flu virus genome in less than 12 hours. We are in the process of building a simple smaller faster converter device, "a digital to biological converter", that in a fashion similar to the telephone where digital information is converted to sound; we can send digital DNA code at the close to the speed of light and convert the digital information into proteins, viruses and living cells. With a new flu pandemic we could digitally distribute a new vaccine in seconds around the world, perhaps even to each home in the future.
Currently all life is derived from other cellular life including our synthetic cell. This will change in the near future with the discovery of the right cocktail of enzymes, ribosomes, and chemicals including lipids together with the synthetic genome to create new cells and life forms without a prior cellular history. Look at the tremendous progress in the 70 years since Schrodinger's lecture on this campus. Try to imagine 70 years from now in the year 2082 what will be happening. With the success of private space flight, the moon and Mars will be clearly colonized. New life forms for food or energy production or for new medicines will be sent as digital information to be converted back into life forms in the 4.3 to 21 minutes that it takes for a digital wave to go from earth to Mars.
I suggested in place of sending living humans to distant galaxies that we can send digital information together with the means to boot it up in tiny space vessels. More importantly and as I will speak to on Saturday evening synthetic life will enable us to understand all life on this planet and to enable new industries to produce food, energy, water and medicine as we add 1 billion new humans to earth every 12 years.
Schrodinger's "What is Life?" helped to stimulate Jim Watson and Francis Crick to help kick off this new era of DNA science. One can only hope that the newest frontier of synthetic life will have a similar impact on the future.
REMARKS BY JAMES D. WATSON
JAMES WATSON: In 1963, which was 10 years after the Double Helix, I began putting together a book which became the Molecular Biology of the Gene. It was before we knew the complete code, it was after what Nirenberg had shown and so I thought we knew the general principles. I thought initially the title we would use for the book was This Is Life, but I thought that will be controversial because I hadn't explained everything, so it just became The Molecular Biology of the Gene.
I want to congratulate Craig on a very beautiful lecture.
Certainly Craig's talk is …it's much more beautiful 60 years later. And everything. I think chemistry is a good thing. I think our finding the DNA structure was unusual in that Crick or I, neither of us knew any chemistry. Luckily there was a chemist in the room, and helped. But I think we're in this era of beautiful high technology. Sentimentally, I hope there's still a role for the biologist.
Time will tell, but I want to congratulate Craig on a very beautiful lecture.
